How I capture every Claude conversation automatically.
A Claude Code hook system, a SQLite database, and 16 months of accumulated thinking.
What this is about
I use Claude heavily — for building, thinking, writing, debugging, designing. Over time I noticed something uncomfortable: I'd have the same conversation twice, sometimes three times, months apart, without realising I'd already explored it. The thinking was there. I just couldn't see it.
Most tools treat this as a retrieval problem. Store the conversations, search them later. But I don't think retrieval is the interesting part. What I wanted was something different: not "what did I say about X?" but "what are the patterns in how I think about X, across everything?"
So I built Signal Mirror — a system that reads my AI conversation history and builds a model of how I think. Not a second brain. Not a RAG system. Not a chatbot. It extracts a structured signal from each conversation — the driving question, the emotional register, the outcome type — and aggregates them. One signal isn't interesting. Hundreds of them start to reveal things that no individual conversation would show.
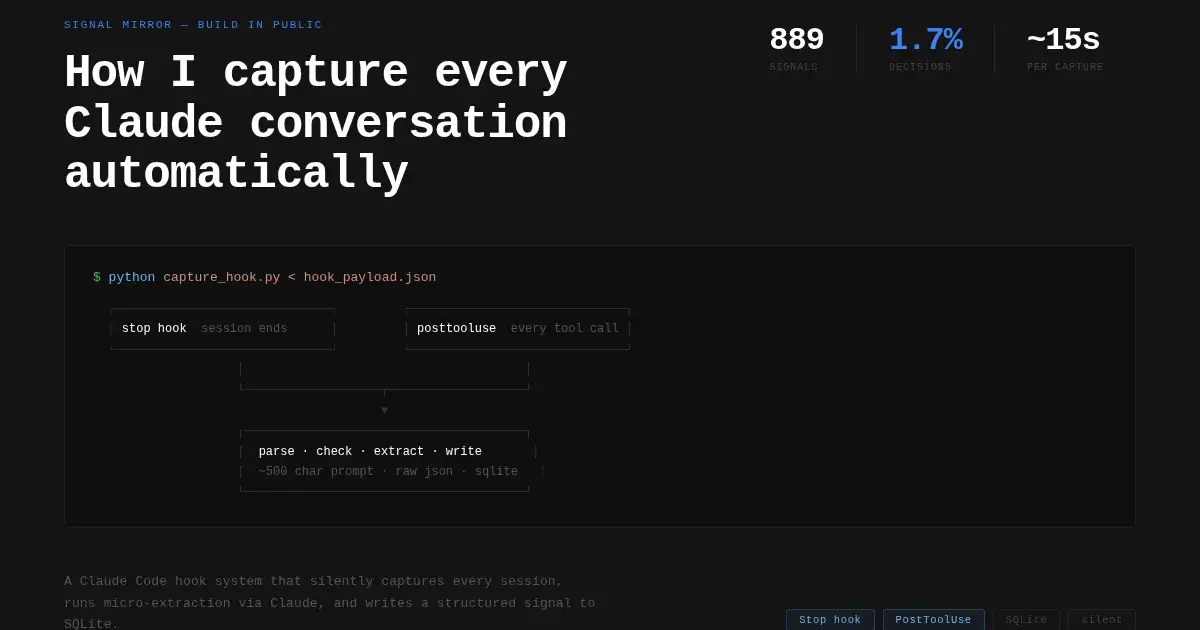
889 signals so far, from 16 months of Claude.ai conversations exported manually and processed in batch. But as I shifted more of my work into Claude Code, I needed a way to capture those sessions too — automatically, without any manual step.
That's what this post is about: the capture hooks that make Claude Code sessions automatic.
Every time I close a Claude Code session, something happens in the background that I didn't set up to notice.
A script fires. It reads the transcript. It decides whether the conversation is worth capturing. If it is, it runs a short extraction prompt against the first six messages and writes a structured signal to a SQLite database.
By the time I've switched windows, it's done.
The 889 signals in Signal Mirror so far came from a different path — Claude.ai conversations, exported manually and processed in batch. The hooks are what make new Claude Code sessions automatic. No export step, no manual trigger. They just run.
Here's how it works.
The entry point: Claude Code's hook system
Claude Code has a hook system. You can configure scripts to run at specific points in the conversation lifecycle — before a tool runs, after a tool runs, when a session ends.
I use two hooks:
Stop — fires when a session ends. The obvious choice for capture.
PostToolUse — fires after every tool call, throughout the session.
The Stop hook alone has one failure mode: long sessions. If a session runs for hours and then crashes, or you close the terminal without /exit, the Stop hook never fires and the session is lost. The PostToolUse hook fixes that — it creates incremental checkpoints throughout the session.
Both hooks point to the same script. The payload is the same either way:
{
"transcript_path": "/path/to/session.jsonl",
"session_id": "abc123..."
}
My hook is a Python script registered in ~/.claude/settings.json. It runs in the background, exits 0 always (never blocks the session), and logs to ~/signal-mirror/capture.log.
What the hook actually does
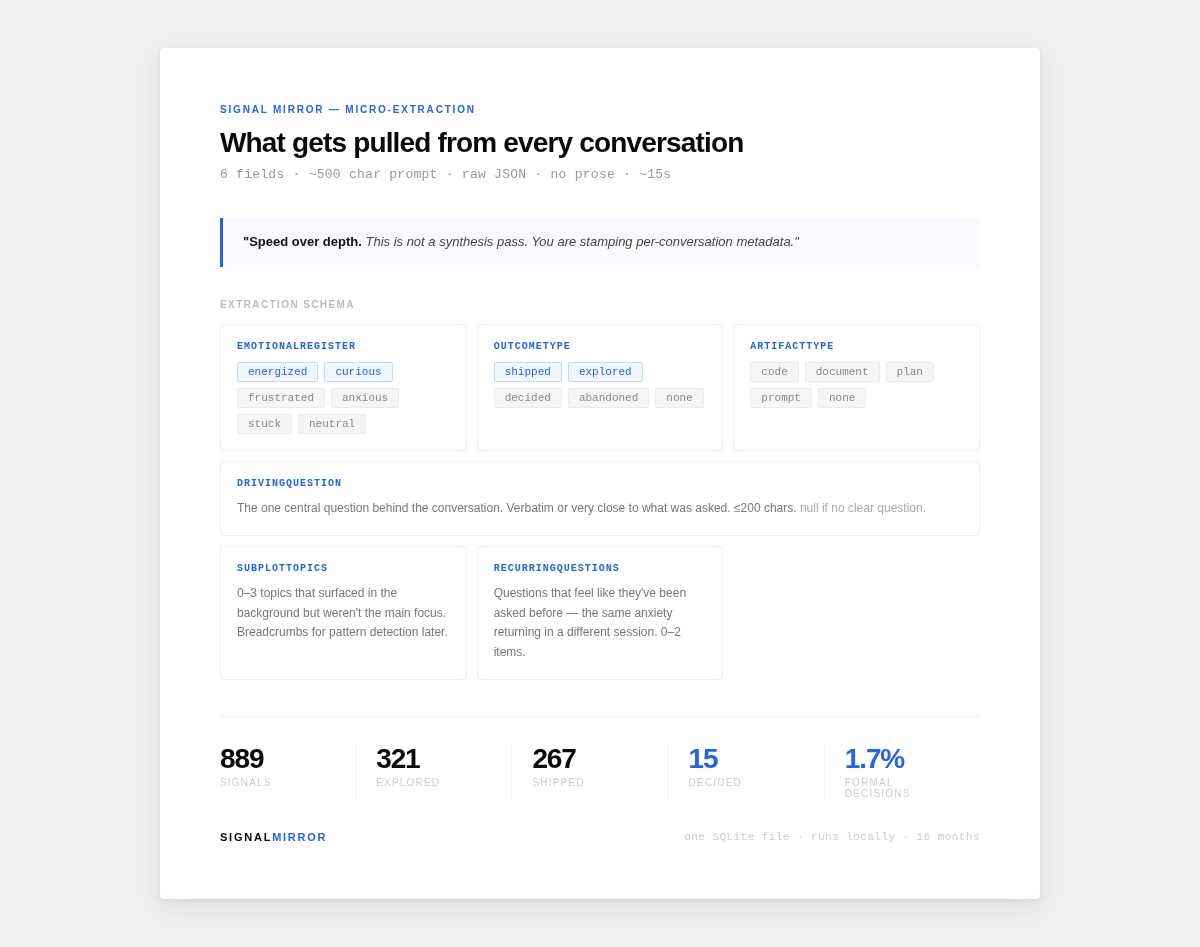
Eight steps, roughly 15 seconds end-to-end:
1. Read the hook payload from stdin Parse the JSON. If transcript_path or session_id are missing — which can happen — log and exit quietly.
2. Parse the JSONL transcript The transcript is a JSONL file — one JSON object per message. A parser walks it and produces a ParsedSession: title, start time, list of human turns, a flag for whether it's substantive.
3. Substantive check If the session has fewer than 2 human turns, skip it. Most of those are test sessions or accidental opens. Not worth capturing.
4. Growth check This one carries more weight now that the hook fires on every tool use. If the session has already been captured, the hook checks whether the conversation has grown by at least 3 new human turns since last capture. If not, it exits immediately — no Claude call, no DB write. The check is a single SQLite read, fast enough to run dozens of times per session without anyone noticing.
Why 3? Arrived at by feel, not by analysis. Enough to mean something new actually happened. Low enough that meaningful checkpoints accumulate in long sessions.
5. Build the micro-extraction prompt Takes the session title and the first 6 human turns (up to 600 chars each). Appends the extraction schema. The full prompt is around 500 characters of instruction plus the conversation fragment.
6. Run Claude One API call. The model reads the conversation fragment and returns a JSON object — no markdown fences, no prose, raw JSON only.
7. Parse into a ConversationSignal The JSON gets parsed into a typed signal with 6 fields. If parsing fails, it logs and exits — no retries, no rethrowing.
8. Write to SQLite The signal gets written to signals.db. Topic assignment runs via keyword matching (no Claude call — fast enough for the live path). Turn count gets stored for the growth check next time.
What gets extracted
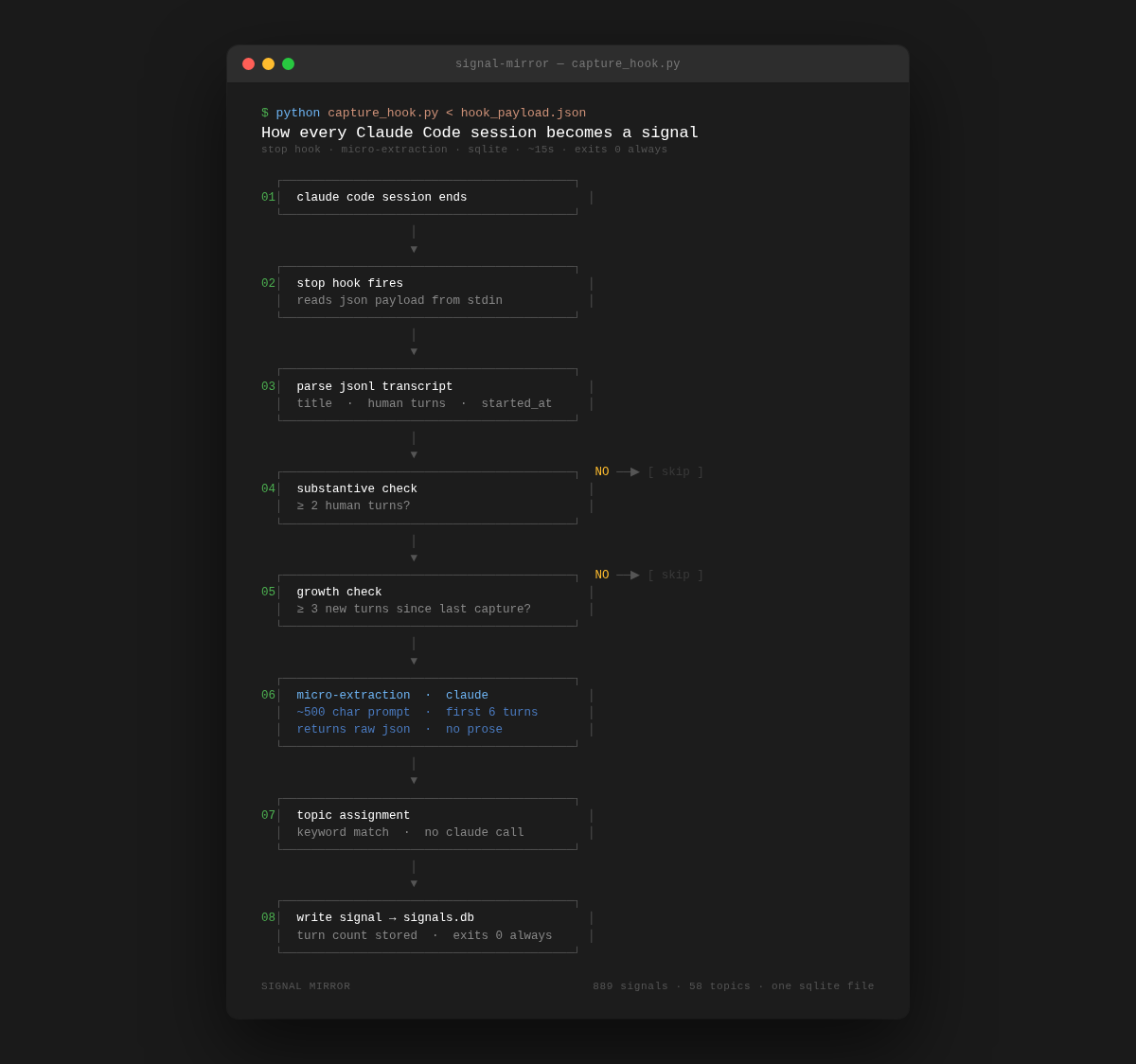
The extraction prompt asks for six things:
emotionalRegister — curious / frustrated / energized / anxious / stuck / neutral
outcomeType — decided / explored / shipped / abandoned / none / ...
artifactType — code / document / plan / prompt / none
drivingQuestion — the one central question, ≤200 chars, verbatim or null
subplotTopics — 0–3 background topics, short labels
recurringQuestions — questions that feel like they've been asked before, 0–2 items
The instruction to the model is: speed over depth. This is not a synthesis pass. You are stamping per-conversation metadata.
One signal from one conversation isn't interesting. But aggregated across hundreds of them, patterns emerge that no individual session would show. The 889 in Signal Mirror were built from Claude.ai exports — the hooks are what make sure Claude Code sessions never get missed going forward.
What 889 signals look like
I didn't expect the outcome distribution to be as sharp as it is:
321 conversations ended in explored
267 ended in shipped
15 ended in decided
1.7% formal decisions. 30% shipped outcomes.
I'm still not sure exactly what to make of that — but it seems like building might just be how I close open questions, not deciding first and building after. The extraction didn't tell me that. The aggregation did.
The frustration pattern is harder to sit with. When the emotional register is frustrated, 50 conversations ended in nothing. When energized, 399 shipped. That gap is pretty unambiguous about what state is worth protecting.
What I'm still figuring out
The extraction quality depends entirely on the quality of the first 6 human turns. Long conversations where the real question emerges later get misread. The PostToolUse hook means those sessions are now captured incrementally — the signal written after turn 4 is different from the one written after turn 30 — but the extraction still reads from the top. A smarter turn selection strategy would help more than more frequent captures.
The growth check (3 new turns) is a heuristic. It works, but the right number probably varies by conversation type. Short debugging sessions reach their real question faster than long architecture conversations. I haven't found a clean way to make it adaptive yet.
And topic assignment at the end of the hook is keyword-only — no embeddings, no Claude call. It's fast, but it misses conceptual matches. A conversation about "distribution bottlenecks" won't match a topic labelled "marketing" unless the word "marketing" appears in the signal fields.
None of these are blockers. They're the gap between the system as it runs and the system as I'd build it now.
The thing that made this work
I think the most important design decision wasn't the extraction schema or the SQLite choice or the two-hook setup. It was making the hook exit 0 always.
If the hook fails, the session still closes normally. There's no feedback loop that makes me want to turn it off. It just quietly fails and logs, and the next tool use tries again.
A hook that occasionally blocked sessions would have been disabled by month two. The Claude.ai conversations still come in via manual export — that's a separate path, a separate step. But Claude Code sessions are now fully automatic, with incremental checkpoints throughout. Both end up in the same SQLite database.
Building Signal Mirror in public. More on the pipeline, the synthesis stages, and what the data keeps surfacing.
Join Abhishek on Peerlist!
Join amazing folks like Abhishek and thousands of other builders on Peerlist.
0
0
0