Agent web-search-API for negligible cost
How I built a custom pipeline by combining web-scraping and a bunch of models to create a robust, fast and scalable search-inference API
The problem: How AI agents require access to internet to operate
Any research platform or AI agent that needs to answer real‑world questions has to pull information from the web. Static knowledge bases go stale overnight. So you need crawling, extraction, chunking, embedding, and retrieval , a live search pipeline. The standard playbook today is to chain together cloud APIs: OpenAI embeddings, Pinecone or a managed vector database, and maybe an external re‑ranker. It works. But it also locks you into recurring costs, network latency, and a data privacy boundary you lose control of the moment you hit Send. For a research tool handling proprietary targets, that wasn’t acceptable. Using searchAPI like Tavily/Exa/perplexity aren't feasible either.
They need different data than humans
Humans can skim a web page and instinctively filter out menus, footers, ads, and cookie banners. AI agents can’t. Feed raw scraped HTML into a vector index and you’ll get search results about “accept cookies” instead of the technical content your user asked for. So the pipeline has to extract the real meat the article body, the meaningful headings, the clean text and discard the rest. That means actually understanding page structure, not just stripping tags. The final data feeding the index must be signal, not noise. And since every chunk gets embedded, even a few sentences of boilerplate pollute retrieval quality over time.
They operate on data
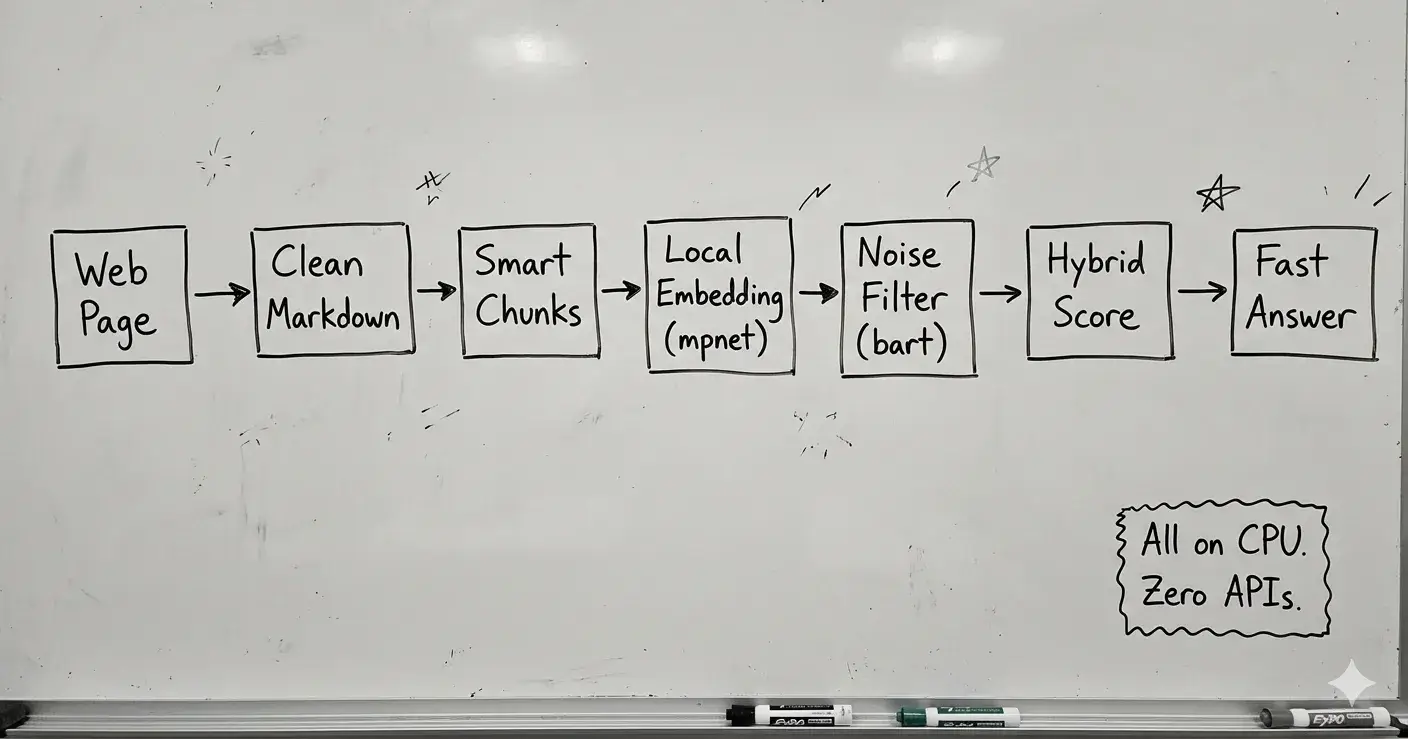
The goal wasn’t to build a chatty assistant. It was to build a deterministic microservice that turns a web page into an addressable, semantic memory. Crawl the URL, extract clean Markdown, split it into token‑aware chunks that never silently truncate, embed each chunk with a local model, classify its quality with a zero‑shot classifier, and store it in an in‑memory index that can be queried in under 80ms. The whole thing runs behind a simple API, sharing a VPS with the rest of the platform. It doesn’t “reason”; it delivers the right chunks, fast, privately, and obediently.
PAID API solutions cost a fortune when scaled
Embedding APIs charge per token. So do classification APIs. Every page you crawl, every chunk you embed, every query your users fire off ka‑ching. At hundreds of pages a day and thousands of chunks, a $0.01‑per‑query sticker price becomes a monthly invoice that grows faster than your user base. And if you run a freemium product, the cost bleeds you dry. By keeping everything local and CPU‑bound on a flat‑rate VPS, the marginal cost per query is zero. The $30/month hosting covers all the crawling, indexing and search you can throw at it. That flips the economics: from a cost centre to a fixed expense you barely think about.
Usage data and metrics are all monitored :you lose privacy
Even with enterprise agreements, when you proxy your data through a third‑party embedding or classification service, you trust their logging policies. Often you can’t control what’s retained, and you certainly can’t audit it. For research platforms that aggregate internal competitor data, early‑stage due‑diligence documents, or confidential technical targets, every outbound API call is a leak. The only bulletproof privacy guarantee is to never let the data leave the machine. So the pipeline was designed to run air‑gapped from any external AI service. No tokens, no pages, no metadata ever cross the network boundary. That’s peace of mind you can’t get from a privacy policy.
The plan
The mandate was straightforward but demanding: build a production‑grade search pipeline that crawls the open web, indexes it, and serves chunk‑level results all on a single $30 VPS with no GPU, no cloud AI APIs, and no per‑query fees. The solution had to share CPU and memory gracefully with an existing research platform, stay under 16 GB RAM, and deliver sub‑100ms query latency at volume. The bet was that quantized open‑source models and careful engineering could replace every line item in the classic RAG bill.
Architecture
Crawling uses Cheerio + Mozilla Readability + Turndown to turn raw HTML into clean Markdown without a headless browser. Chunking is sentence‑aware and token‑precise, respecting the embedding model’s context limit and never splitting words. The embedding model is all-mpnet-base-v2 quantized to int8, generating 768‑dim vectors fully on CPU. A second model, bart-large-mnli quantized to int4, acts as a zero‑shot noise detector, scoring each chunk for labels like “useful content” versus “navigation menu” or “cookie banner.” The classification gives a quality weight that fuses with cosine similarity in a hybrid scoring formula: final_score = cosine_similarity × quality_weight^0.5. All embeddings sit in an in‑memory FAISS index for instant retrieval. Everything is wrapped in a FastAPI microservice backed by SQLite for crawl state.
Solution
The pipeline runs as a background citizen on the VPS, processing 50+ pages per minute with concurrent crawl and embed workers. Median search latency is below 80ms no network round‑trip, no rate throttling. Memory footprint stays under 6 GB, leaving ample room for the host platform. The hybrid scoring strongly suppresses boilerplate noise that would otherwise degrade results, and token‑aware chunking prevents the fragmented answers that plague naive RAG setups. Privacy is absolute; cost is flat. And it all runs on CPU, proving that you don’t need a GPU farm or an API key to ship great retrieval.
Pros and cons
Pros: Zero marginal cost, deterministic latency, complete data privacy, no external dependencies, simple deployment. The open‑source models are genuinely production‑grade for retrieval and noise classification when quantized, and the hybrid scoring adds a meaningful quality lift over raw vector similarity.
Cons: You’re capping your top‑end embedding quality at mpnet (no huge LLM‑based embeddings), and the zero‑shot classifier, while effective, isn’t perfect on edge‑case boilerplate. CPU‑only embedding means you’ll saturate cores during a spike, so tight worker management is required. And you trade the convenience of a fully managed vector DB for an in‑memory index you have to rebuild from SQLite on restart a trivial overhead for this scale, but a design point to be aware of. There is still one thing left. If you can crank up the hardware to GPUs/TPUs then you do not need any other API at all.
The real insight? The industry has normalised the idea that good AI needs cloud APIs. But with a little quantisation and a dose of systems thinking, a single CPU box turns into a shockingly capable, private, and predictably cheap search engine. You might not need OpenAI after all.
Join Ayush on Peerlist!
Join amazing folks like Ayush and thousands of other builders on Peerlist.
0
7
0