A Practical Framework for Testing LLM and RAG Systems
Most people misunderstand why evaluating LLM and RAG systems is hard.
It’s not because AI is complex.
It’s because𝐨𝐮𝐫 𝐨𝐥𝐝 𝐭𝐞𝐬𝐭𝐢𝐧𝐠 𝐚𝐬𝐬𝐮𝐦𝐩𝐭𝐢𝐨𝐧𝐬 𝐛𝐫𝐞𝐚𝐤.
Traditional QA assumes:
• Deterministic inputs
• Predictable outputs
• Clear expected results
LLMs break all three.
That’s the problem DeepEval is designed to solve.
What is DeepEval
DeepEval is an 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧 𝐟𝐫𝐚𝐦𝐞𝐰𝐨𝐫𝐤, not an observability tool and not a chatbot wrapper.
Its job is simple but non-negotiable:
Turn subjective AI outputs into𝐨𝐛𝐣𝐞𝐜𝐭𝐢𝐯𝐞, 𝐭𝐞𝐬𝐭𝐚𝐛𝐥𝐞 𝐬𝐢𝐠𝐧𝐚𝐥𝐬.
It does this by:
• Treating LLM responses as 𝐚𝐫𝐭𝐢𝐟𝐚𝐜𝐭𝐬 𝐭𝐨 𝐛𝐞 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐞𝐝
• Using structured metrics instead of text matching
• Applying repeatable evaluation logic you can run in CI
In QA terms:
DeepEval replaces “looks fine to me” with 𝐚𝐬𝐬𝐞𝐫𝐭𝐢𝐨𝐧𝐬.
The real problem with RAG systems
RAG failures are rarely model failures.
They usually happen in one of these layers:
1. Retrieval layer
Wrong documents fetched, partial context, noisy chunks
2. Prompt layer
Prompt encourages guessing instead of grounding
3. Generation layer
Model blends real context with invented facts
4. Evaluation layer
Nobody checks if the output is actually valid
DeepEval doesn’t guess where things went wrong.
It 𝐢𝐬𝐨𝐥𝐚𝐭𝐞𝐬 𝐭𝐡𝐞 𝐟𝐚𝐢𝐥𝐮𝐫𝐞 𝐦𝐨𝐝𝐞.
DeepEval’s metric design
DeepEval doesn’t use one vague “accuracy” score.
It decomposes quality into orthogonal metrics.
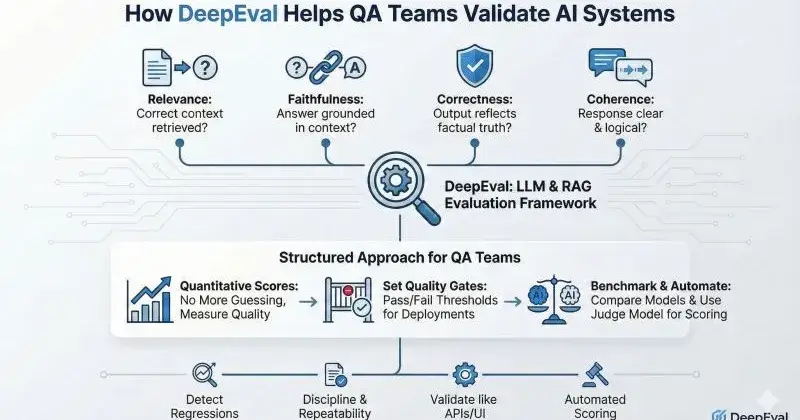
1. Answer Relevancy
Checks whether the response actually answers the user question.
This catches:
• Long but useless answers
• Overly generic responses
• Hallucinated tangents
This is critical for chatbots that sound confident but say nothing.
2. Faithfulness
This is the most important RAG metric.
Faithfulness asks:
Is every claim in the answer 𝐬𝐮𝐩𝐩𝐨𝐫𝐭𝐞𝐝 𝐛𝐲 𝐭𝐡𝐞 𝐫𝐞𝐭𝐫𝐢𝐞𝐯𝐞𝐝 𝐜𝐨𝐧𝐭𝐞𝐱𝐭?
If the model invents even one unsupported fact, the score drops.
This is how DeepEval detects hallucinations without needing ground truth.
3. Context Precision
Measures how much of the retrieved context was actually useful.
Low precision means:
• Too many irrelevant chunks
• Poor chunking strategy
• Weak embedding similarity
This is a retrieval quality problem, not a model problem.
4. Context Recall
Measures whether the retrieved context was sufficient to answer the question.
Low recall means:
• Missing documents
• Over-aggressive filtering
• Bad retrieval parameters
Together, precision + recall give QA teams 𝐡𝐚𝐫𝐝 𝐞𝐯𝐢𝐝𝐞𝐧𝐜𝐞 of retrieval issues.
5. Correctness (when ground truth exists)
When you do have expected answers, DeepEval can validate factual accuracy.
This is useful for:
• Knowledge base Q&A
• Internal policy bots
• Compliance-heavy domains
The “𝐋𝐋𝐌 𝐚𝐬 𝐚 𝐣𝐮𝐝𝐠𝐞” concept (and why it’s not reckless)
Many teams panic when they hear this.
Here’s the thing:
DeepEval doesn’t blindly trust another LLM.
It uses controlled evaluation prompts with strict criteria.
Key safeguards:
• Deterministic temperature settings
• Explicit scoring rubrics
• Repeatable evaluation runs
You’re not asking the model:
Is this good?
You’re asking:
Does this answer meet these specific constraints?
That’s a huge difference.
How QA teams actually use DeepEval in practice
This is where it gets real.
Regression testing for AI
Change a prompt?
Update embeddings?
Switch vector DB?
DeepEval catches quality regressions before production.
Same mindset as API regression testing.
Quality gates in CI
You can define rules like:
• Faithfulness score must be ≥ 0.8
• Relevancy must not drop below baseline
• No hallucination flags allowed
Fail the build if AI quality degrades.
That’s real QA control.
Model benchmarking
Compare:
• GPT vs Claude
• OpenAI vs open-source
• Old model vs new model
Using the same test set and metrics.
No opinions. Just data.
Risk-based AI testing
Not all answers need to be perfect.
DeepEval allows you to:
• Accept lower scores for casual chat
• Enforce strict thresholds for legal, healthcare, finance
QA finally gets risk classification for AI outputs.
What DeepEval changes for QA mindset
This is the biggest shift.
QA stops testing:
What did the model say?
QA starts testing:
• Did it stay grounded?
• Did it retrieve the right knowledge?
• Did it exceed acceptable risk?
• Did quality regress over time?
AI testing becomes 𝐬𝐲𝐬𝐭𝐞𝐦 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧, not sentence review.
The uncomfortable truth
If you’re shipping LLM or RAG systems without DeepEval or something similar:
You are not testing AI.
You are𝐡𝐨𝐩𝐢𝐧𝐠.
Hope is not a strategy.
Especially in production.
QA folks, what’s been harder for you so far: testing retrieval or controlling hallucinations?
Join Bharat on Peerlist!
Join amazing folks like Bharat and thousands of other builders on Peerlist.
0
4
0