BindWeave — Subject-Consistent AI Video Generation via Cross-Modal Integration
A new approach to AI video that keeps every subject consistent — even across scenes.

I stumbled upon something genuinely cool in the AI video space this week — BindWeave.
If you’ve ever played with text-to-video tools, you’ve probably noticed how the “same person” never quite stays the same across shots. Faces shift, colors flicker, and consistency falls apart.
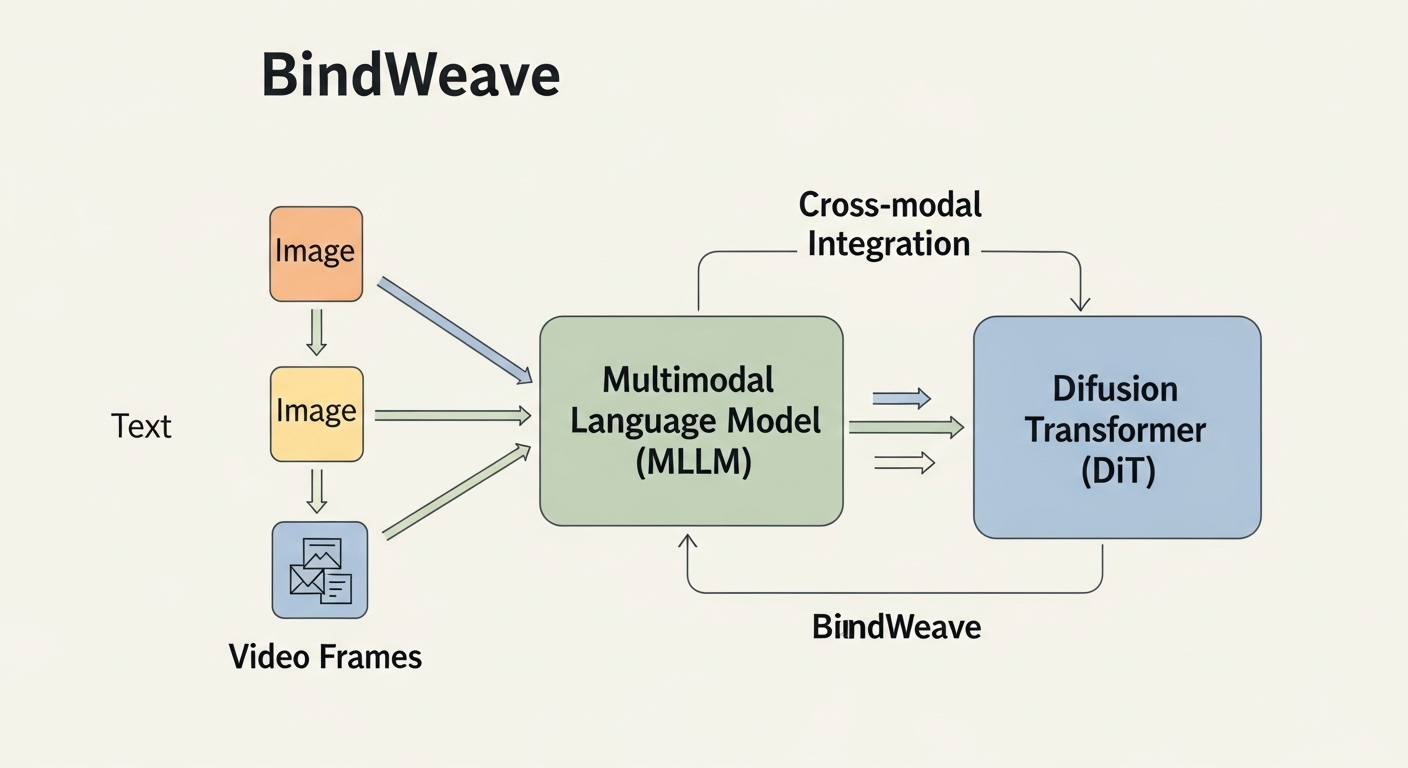
BindWeave takes a crack at fixing that.
It’s a subject-consistent video generation model built on a cross-modal MLLM-DiT architecture, combining a multimodal large language model with a diffusion transformer.
In simpler terms, it connects text and visual understanding so the model actually knows who each subject is — and keeps them consistent throughout the video.
The results are pretty wild. You can feed it text and reference images, and it produces multi-subject, identity-stable videos that look smooth and coherent.
Think digital avatars that stay recognizable, or cinematic scenes where all characters actually remain themselves from start to finish.
I’m not part of the team — just someone who enjoys seeing progress in this direction — but BindWeave feels like one of those quiet leaps forward for generative video.
The demos are up here if you want to see it in action → https://www.bindweave1.com

Would love to hear what others experimenting with cross-modal video generation, identity preservation, or AI filmmaking think about this approach.
Join michael on Peerlist!
Join amazing folks like michael and thousands of other builders on Peerlist.
0
0
0