/prompt-analyzer — find hidden bugs in your LLM prompts before your users do
How a 2026 paper about constraint processing in neural networks helped me build a prompt analyzer that caught a logical contradiction invisible to 4 months of manual review
The Problem
Most prompt engineering advice is vibes-based. "Be specific." "Give examples." "Use system prompts."
I wanted something measurable. Found a fresh paper from University of Milan that actually probed what happens INSIDE the model when it follows instructions. I have been engaged in prompt engineering and studying scientific articles for several years.
The latest research really caught my attention - https://arxiv.org/abs/2604.06015
The answer: there is no single "instruction module." The model coordinates separate skills across different network layers. And that coordination can fail.
The Research (What I Built On)
Rocchetti & Ferrara tested 9 tasks across 3 models (Llama 8B, Gemma 2B, Qwen 0.5B). Key findings:
- Structural constraints (word count, JSON format) activate in early layers
- Semantic constraints (topic, sentiment) activate in late layers
- When you mix all 4 types in one prompt, there's minimal representational sharing between them
- The model doesn't pre-plan constraint satisfaction—it monitors dynamically during generation
- Constraints mentioned earlier get monitored longer
This isn't theory. They measured it with diagnostic probing, cross-task transfer analysis, and causal ablation.
What I Built
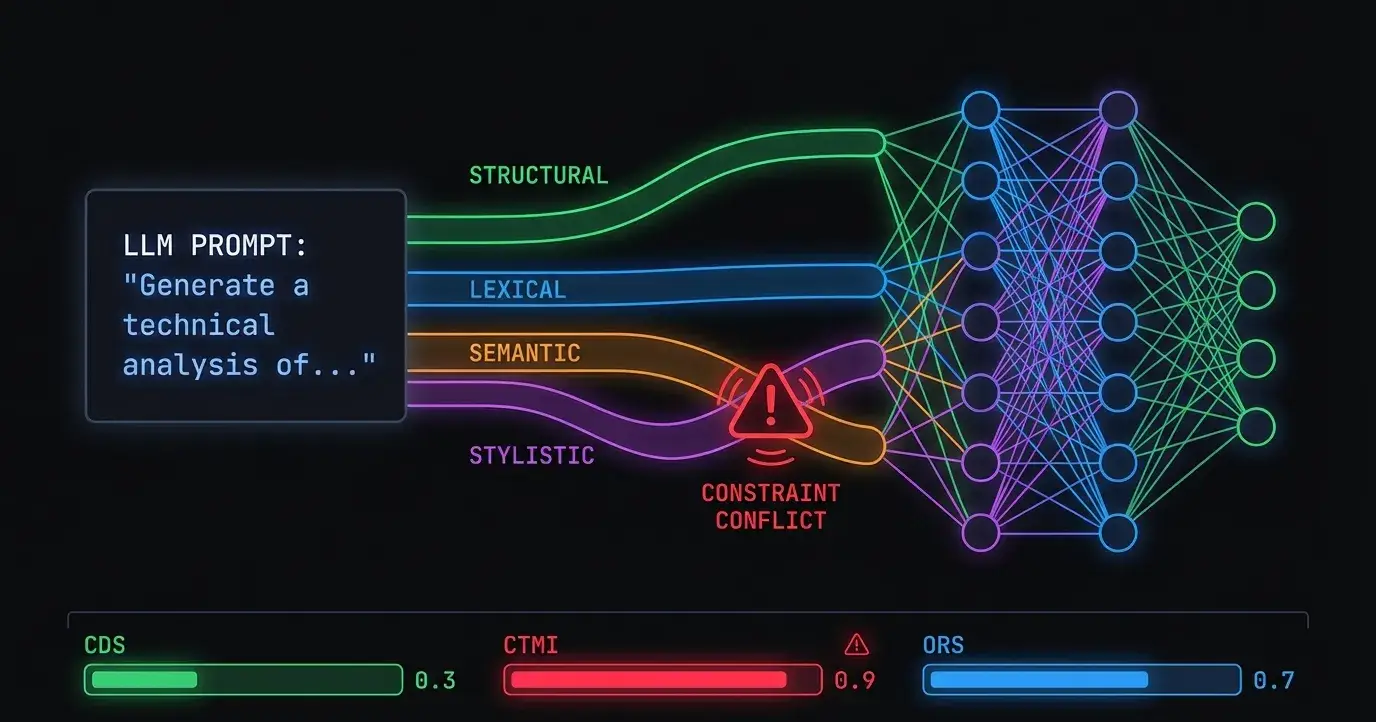
A /prompt-analyzer skill that scores any prompt on 3 metrics:
1. Constraint Density Score—total constraints per prompt. 8+ = the model WILL drop some.
2. Cross-Type Mixing Index (CTMI)—how many constraint types are mixed (structural / lexical / semantic / stylistic). 1 type = 0.0 risk. All 4 types = 1.0 risk. Each implicit constraint or conflict adds +0.1.
3. Order Risk Score—are semantic constraints placed before structural ones? Research shows: earlier = monitored longer. Semantic constraints need more monitoring. Putting format rules first and topic last is literally backwards.
Output: audit findings ranked by severity + rewritten variants optimized for Claude and GPT separately.
Our Numbers
Ran it on 3 production LLM prompts powering our platform's AI validation pipeline (scoring, quality checks, content improvement).
Results:
- 8 findings across 3 prompts
- 1 CRITICAL—a direct logical contradiction between two rules in the same prompt
- 2 out of 3 prompts (67%) needed rewrite
- Average CTMI: 0.77 (high—all prompts mixed 4 constraint types)
- Worst prompt: 12 constraints, CTMI 0.9, density rating CRITICAL
The best prompt scored CTMI 0.6 with OPTIMAL order—persona first, evaluation criteria second, output format last. We now use it as the internal reference pattern.
A/B Test on Production
Took the worst prompt (the one with the CRITICAL conflict) and ran both versions against a real task on the same model, same temperature.
Before (original prompt):
- Generated 6 evaluation checkpoints
- 1 checkpoint was fabricated—referenced validation against data that didn't exist in the source
- Imposed a single solution approach, ignoring an alternative from the task description
- 6 structural bullet points
After (optimized prompt, -3 lines of code):
- Generated 7 evaluation checkpoints (+17%)
- 0 fabricated items—every checkpoint traceable to source data
- Preserved both solution approaches from the original task description
- 14 structural bullet points (+133%)
The conflict was: "add evaluation criteria if missing" + "don't add information user didn't provide." Model couldn't satisfy both, so it randomly invented content. One line fix: "derive criteria ONLY from information already present." Zero hallucinated content after.
Open Source
The skill is free. MIT. Works with Claude Code, Codex, Gemini CLI, Droid—any agent that reads .md files.
npx @citedy/skills install prompt-analyzer
Feed it a file with your prompts separated by ---. Get: constraint map, scores, audit findings, and rewritten versions for Claude and GPT.
If you're running LLMs in production, your prompts probably have conflicts you don't know about. We didn't know about ours until we looked.
Join Dmitry on Peerlist!
Join amazing folks like Dmitry and thousands of other builders on Peerlist.
0
2
0