Building an OpenEnv-compliant incident triage environment for RL -what I learned along the way
April 2026. Hackathon weekend. Coffee count: 4. ~36hrs
I want to walk through what I built, why I built it the way I did, and the things that mattered (and the things that very much didn’t) when teaching a 1.5B-parameter Qwen to behave like a half-decent oncall engineer.
This is a long post. There are diagrams. There are tradeoffs I had to make and would do differently next time. If you only have two minutes, read the section called “Why per-step grading is the entire point” and skip the rest.
The problem I wanted to solve
I’ve been on call. Every engineer who ships code eventually gets paged at 3 AM and has to do this dance:
Stare at the alert. Try to figure out which service is actually unhealthy vs. which one is just downstream of something else.
Open four browser tabs — Datadog, Sentry, GitHub, the chat where someone is already speculating wildly.
Form a hypothesis. Validate it against the data. Discard it. Form another.
Decide what fix to ship — but only if the change-freeze window allows forward-fix PRs, which it usually doesn’t, which means rollback. And before rolling back, you’d better have paged the on-call lead.
Write an incident ticket. Estimate blast radius. Open a PR. Stand up at standup tomorrow and explain what happened.
That whole loop is sequential decision-making under uncertainty with sparse, delayed reward signals across multiple tools. Which is to say — it’s an RL problem, hiding in plain sight.
The hackathon theme — “World Modeling: Professional Tasks” — was the excuse I needed to actually build it.
But here’s the thing that bothered me about most published RL benchmarks for agents: they reward outcomes. Did the agent get the right answer at the end? Yes/no. That’s not how oncall reasoning works. Oncall reasoning is a process. You can arrive at the right answer by accident, you can arrive at the wrong answer with impeccable methodology, and a senior SRE evaluating a junior’s incident postmortem cares about both.
So when I sat down to design the environment, the first decision I made was:
Reward the process, not just the outcome.
Everything else — the architecture, the action space, the multi-app dispatcher, the scoring math — flows from that one constraint.
Why per-step grading is the entire point
Most RL environments I’ve worked with hand the agent a sparse terminal reward. You take 20 steps, you submit, you get a number between 0 and 1. The intermediate steps are graded only through credit assignment by the optimizer.
For incident triage, that’s wildly insufficient. Consider two trajectories that both end with the correct diagnosis:
Trajectory A: agent immediately runs the oracle path. 5 steps, perfect causal chain, paged on-call before submitting rollback.
Trajectory B: agent flails for 18 steps, queries every service three times, ignores world events, never pages anyone, and stumbles into the right answer.
A pure terminal grader gives both the same score. My env gives Trajectory B about a third of A’s reward, because every step gets graded:
The
InvestigationRubricscores informational value (direct evidence > causal-chain evidence > contextual > redundant).The
PolicyEnginescores operational discipline against declarative business rules (you got a +0.10 for paging before rollback, you got a −0.25 for opening a forward-fix PR during the change-freeze).The terminal
CompositeScoreris the cap, not the signal.
This means the reward landscape is dense and interpretable. Every action returns a number. Every step the agent can see whether the env approved or disapproved of what it just did. That’s the kind of signal an RL training loop can actually optimize against in 100 GRPO iterations rather than 10,000.
If you remember nothing else from this post: dense, multi-source, real-time scoring is what makes this env trainable.
What I actually built -
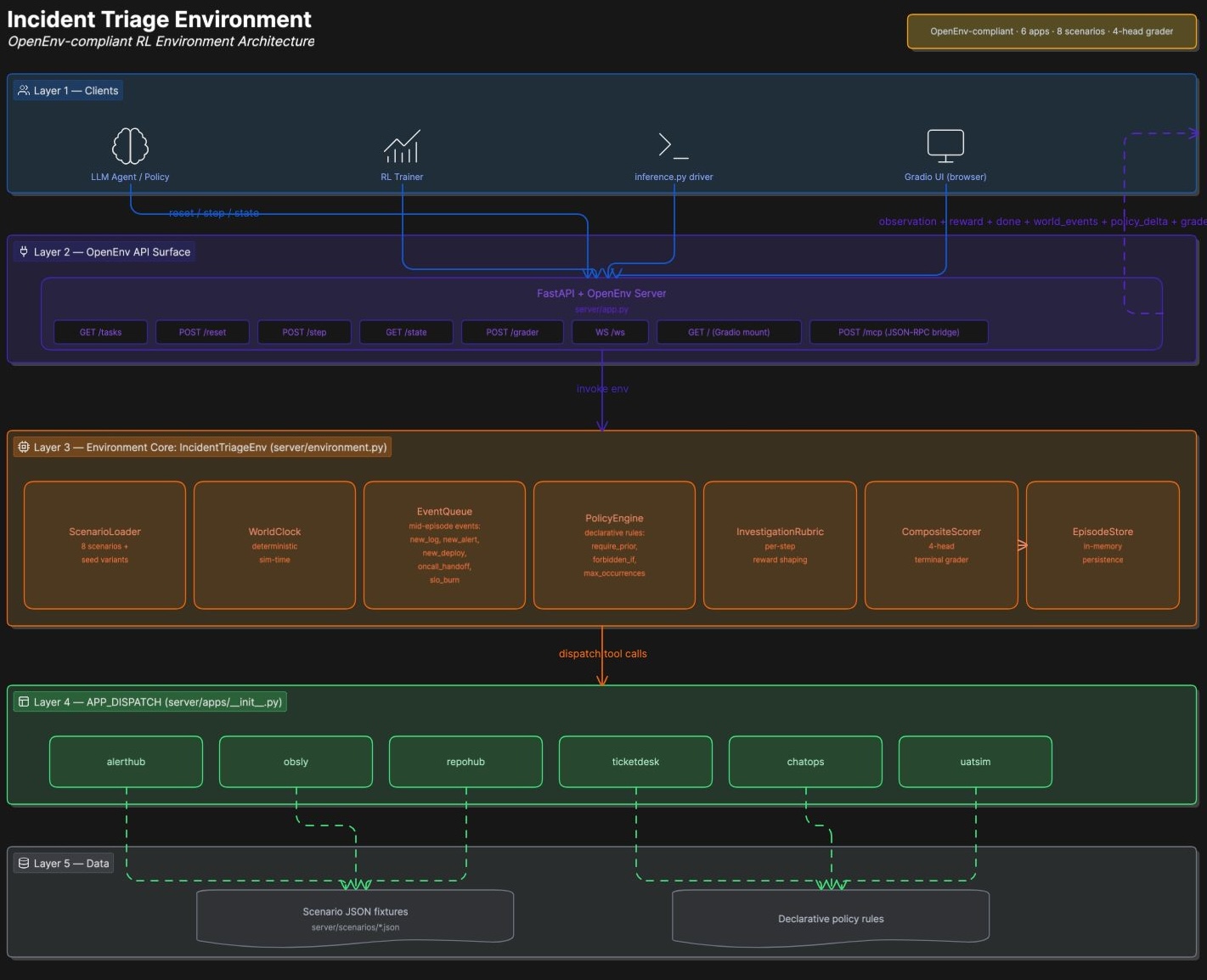
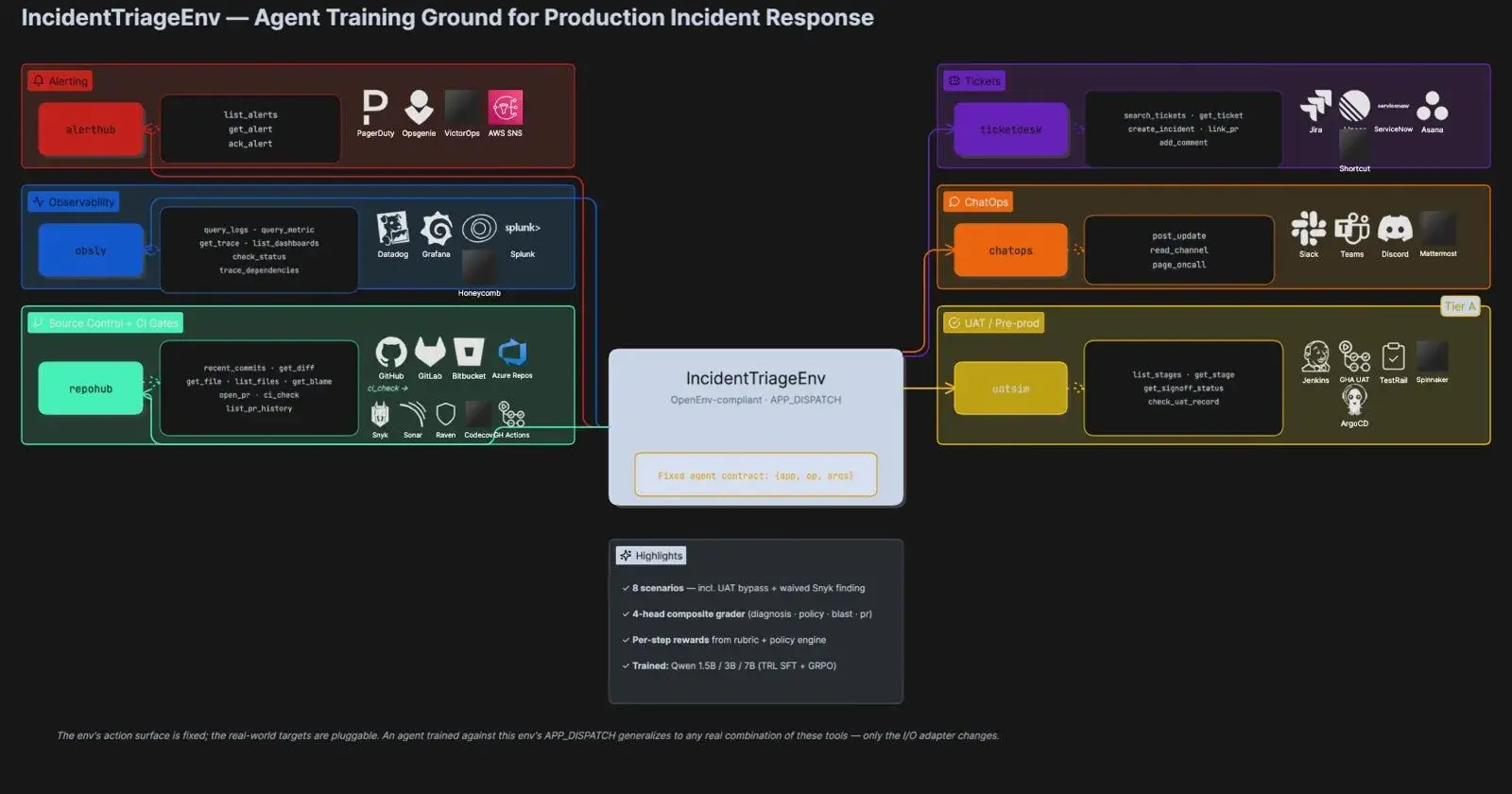
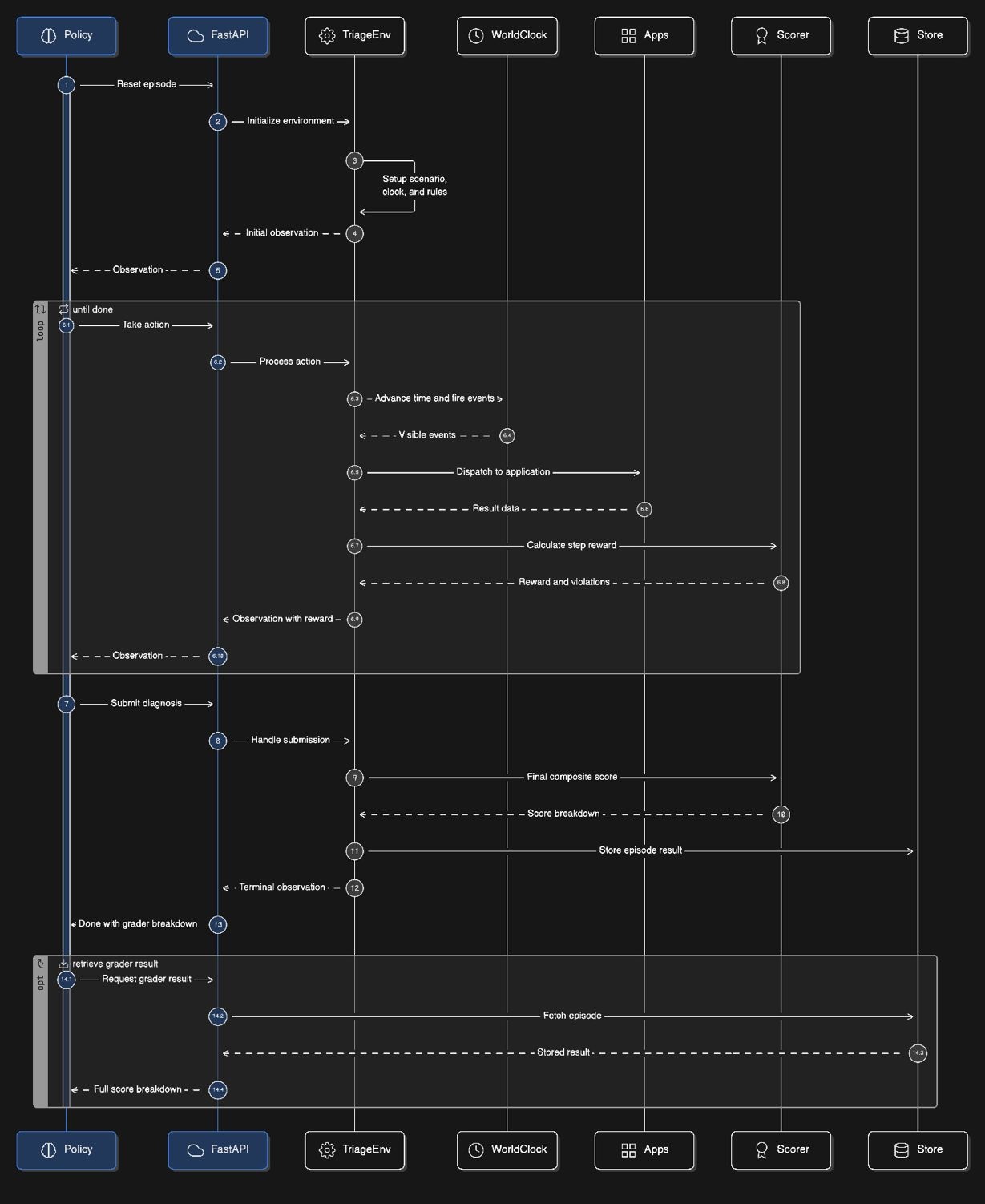
The bones are standard OpenEnv:
IncidentTriageEnv.reset(task_id, seed?)loads a scenario, deep-copies it (to prevent cross-episode bleed), spins upWorldClock,EventQueue,PolicyEngine, andInvestigationRubricinstances, and returns the initial alert.step(action)advances sim-time, fires due timeline events, dispatches the action to one of six app handlers, applies the policy delta and rubric reward, and returns an observation. The observation includes the action result, the current sim-time, any world events that fired this tick, the per-step policy delta, and the list of policy rules that were triggered.On
submit_diagnosis,_handle_submitruns the 4-head composite grader, packs the breakdown into the terminal observation, and stores the episode for later/graderretrieval.
The interesting parts are everything around that core loop.
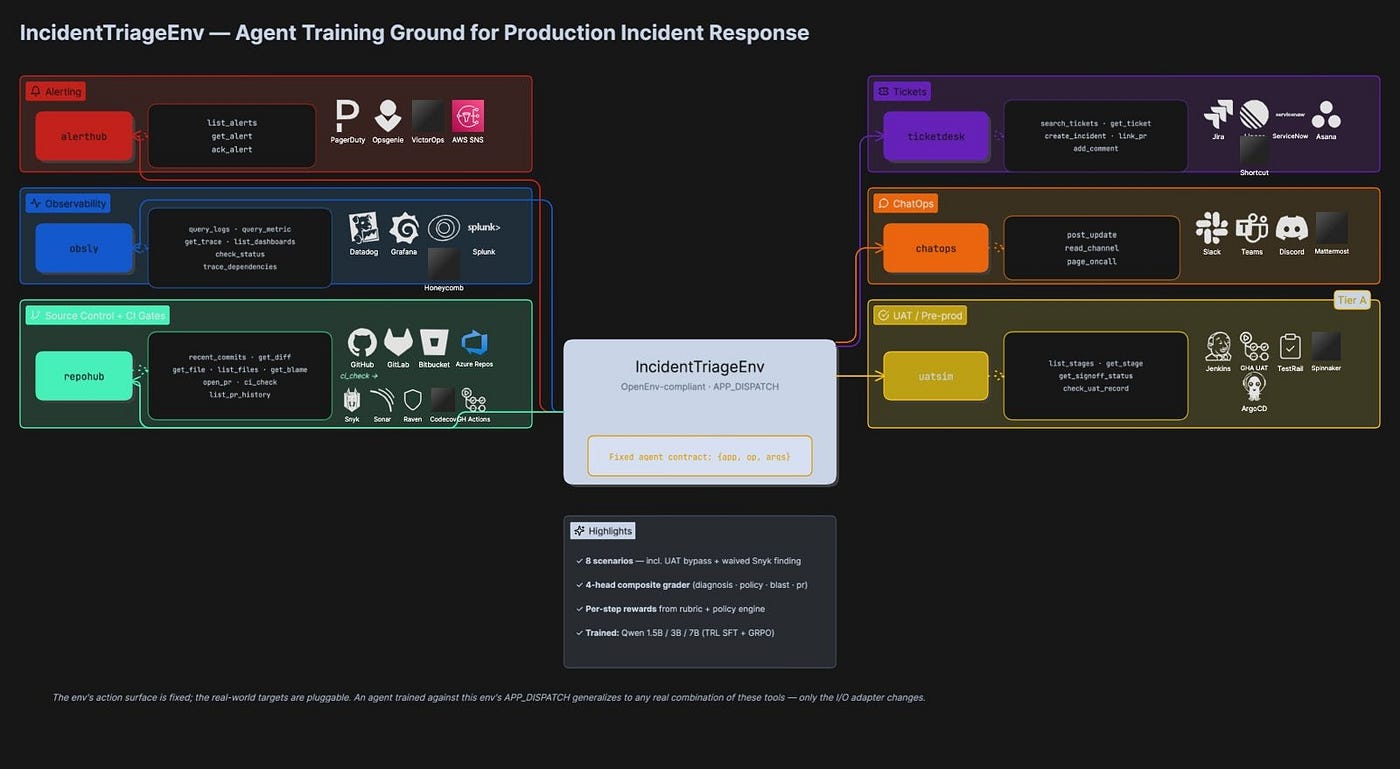
The multi-app dispatcher
Real oncall doesn’t happen in a single tool. So I split the env’s action surface across six apps that mirror real enterprise systems:
Two of those — repohub.ci_check and the entire uatsim app — are what I called the "Tier A" expansion. They model process-hygiene gates: the things that, if your team is sloppy about them, cause the incidents in the first place. Two of my eight scenarios revolve around exactly that failure mode (a UAT-bypassed deploy that nukes the guest checkout flow, and a PR merged past a waived Snyk finding that introduces an SSRF vector).
Two of those — repohub.ci_check and the entire uatsim app — are what I called the "Tier A" expansion. They model process-hygiene gates: the things that, if your team is sloppy about them, cause the incidents in the first place. Two of my eight scenarios revolve around exactly that failure mode (a UAT-bypassed deploy that nukes the guest checkout flow, and a PR merged past a waived Snyk finding that introduces an SSRF vector).
Mechanically, the dispatcher is dead simple:
APP_DISPATCH: Dict[str, Dispatcher] = {
"alerthub": alerthub.dispatch,
"obsly": obsly.dispatch,
"repohub": repohub.dispatch,
"ticketdesk": ticketdesk.dispatch,
"chatops": chatops.dispatch,
"uatsim": uatsim.dispatch,
}Each dispatch(op, args, scenario, state, clock) returns a string. That's the whole abstraction. New tool? New module, new dispatch entry, done. No env changes.
The action model itself is a tagged union — {app, op, args} — but with a Pydantic before-validator that auto-migrates the legacy Round-1 shape ({action_type, service, ...}) so older clients don't break. That migration was the single most useful one-hour decision I made; it kept the inference script and the rubric scoring code Round-1-compatible without me having to fork either of them.
The dynamic world
Press enter or click to view image in full size
WorldClock ticks deterministically — every step() advances sim-time by step_seconds (configurable per scenario, default 30 s). EventQueue reads a timeline array from the scenario JSON and fires events at the configured step:
"timeline": [
{ "at_step": 3, "event": "slo_burn", "service": "api-gateway",
"payload": { "burn_rate_x": 10.0 } },
{ "at_step": 6, "event": "new_alert",
"payload": { "id": "PG-RF-3", "severity": "critical",
"service": "traffic-router",
"message": "us-east-1 still stuck — escalations in" } },
{ "at_step": 11, "event": "new_log", "service": "traffic-router",
"payload": { "severity": "warn",
"message": "manual override endpoint not called" } }
]Five event types are supported: new_log, new_alert, new_deploy, oncall_handoff, slo_burn. Events with visible: false mutate the world but don't surface on the observation — the agent has to re-poll to discover them. That's the substrate for one of my favourite scenarios, expert_stealth_regression: a model-server deploy bumps ensemble size from 3 → 7, p99 latency drifts up silently with zero error logs, and the agent has to figure out the regression by looking at metrics rather than waiting for the env to surface an explicit alert.
A static benchmark would never catch a model that just pattern-matches on error log frequency. A dynamic env will.
Declarative policies
The PolicyEngine is one of those abstractions that took me three rewrites to get right. The first version was procedural Python — explicit if action.app == "system" and prior_action_was_page_oncall... blocks. Unmaintainable. Second version had a tiny DSL with too many features. Third version is what shipped: scenario-level JSON rules with a fixed schema:
{
"id": "page-before-config-fix",
"when": {
"app": "system",
"op": "submit_diagnosis",
"args_match": { "remediation": "fix_config" }
},
"require_prior": { "app": "chatops", "op": "page_oncall" },
"require_prior_within_steps": 12,
"penalty": -0.2,
"bonus": +0.1
}The supported predicates are args_match, require_prior, require_prior_within_steps, max_occurrences, and forbidden_if(scenario_tag=...). That's it. Scenarios opt into rules by setting tags (e.g. change_freeze, snyk_high_open, uat_bypassed). The same engine produces both the per-step delta (used in the dense reward signal) and the compliance_score head used in the terminal grade.
The lesson here, which I keep relearning: when in doubt, declarative > imperative for game/env rules. A new scenario shouldn’t require a new code path; it should require a new JSON file.
The 4-head composite grader
The terminal grade is a weighted sum across four heads:
composite = 0.40 · diagnosis + 0.20 · policy
+ 0.20 · blast + 0.20 · prEach head is its own scorer:
diagnosis is the closest to a traditional “did you get the right answer” head. Root-cause-service exact match (with one-hop partial credit), category exact match (with same-failure-family partial credit), remediation match, evidence-coverage proportion, efficiency, plus penalties for shotgun submission, circular investigation, and destructive-remediation-without-deploy.
policy is
(1 - violation_weight / total_attempts)fromPolicyEngine.summary(). Saturates near 1.0 if the agent doesn't violate anything; tanks fast under repeated violations.blast is the impact-reconstruction head. Agent submits a
blast_radiuspayload; we score F1 onaffected_services, F1 onmissed_regions, log-tolerant magnitude onestimated_requests_failed(within 0.5 dex of ground truth = full credit), and IoU on the outage time window.pr scores the structured PR proposal — exact
target_repomatch, recall overtouched_filesreferences in the diff_patch/summary, keyword coverage in title+summary, and structural validity.
The clever bit (or at least the bit I’m proud of): inapplicable heads redistribute their weight. If a scenario has no correct_pr ground-truth, the PR head's 0.20 weight rolls into diagnosis + policy + blast proportionally. If the agent just doesn't submit a pr_proposal, same thing. That keeps the env friendly to Round-1-shaped agents while also rewarding agents that do fill in the structured fields.
One detail I tripped over for an embarrassing amount of time: the OpenEnv evaluator rejects 0.0 and 1.0 exactly. So the final composite score is clamped to (0.001, 0.999). That's why my "perfect" oracle scenarios cap around 0.85 instead of 1.0.
The training journey (this is where things got chaotic)
I’ll be honest: I burned a lot of compute credits debugging things before getting a clean training run. In the spirit of writing the post I wish someone had handed me on Day 1, here’s what actually happened.
Setup
I targeted Qwen-2.5–1.5B-Instruct as the base. Why 1.5B and not 3B? Memory math.
GRPO is memory-hungry because for every prompt you need:
The current policy in GPU memory.
The reference policy (KL target) in GPU memory.
KV caches for
group_sizesimultaneous generations.Gradients + optimizer state (LoRA-only, but still nonzero).
Activations during the forward pass.
For a T4 (15 GB), Qwen-3B is right at the memory edge — sometimes works, often OOMs, never enjoyable. Qwen-1.5B fits comfortably with group_size=4 and max_new_tokens=512. I rewrote my hyperparameters to T4+1.5B once I'd seen Qwen-3B die three times in a row.
Plan A: Pure GRPO
Initial pipeline was straight TRL GRPOTrainer + LoRA, single-turn formulation. The model emits a JSON-action trajectory in one generation; I parse it line-by-line, replay it through a fresh env copy, and the composite score becomes the reward.
def make_reward_func():
def _reward(prompts, completions, **meta):
scores = []
for i, comp in enumerate(completions):
actions = parse_actions_from_completion(comp)
scores.append(replay_and_grade(meta["task_id"][i],
meta["seed"][i], actions))
return scores
return _rewardClean in theory. In practice, on T4 with gradient checkpointing on, each GRPO step took ~9 minutes. 100 iters would take 17 hours. At T4’s $0.40/hr that’s ~$7 — within budget, but not within hackathon weekend.
I also fought a series of nontrivial issues:
FSDPModuleimport error — TRL 0.18+ requires torch ≥ 2.5; the CUDA base image had torch 2.4. Pinnedtrl==0.15.2.element 0 of tensors does not require grad— gradient graph severed at the frozen base-layer boundary because of grad-checkpointing + LoRA. Fix:model.enable_input_require_grads()to register the embedding-output hook.OOM at iter 3 — I had disabled grad-checkpointing thinking the require-grads fix made it unnecessary. Wrong. Turned it back on, added
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True.
By the time I had a clean GRPO run going, I’d already burned ~$1.50 on debug cycles and was watching iter 2 finish at the 20-minute mark.
Time to pivot.
Plan B: SFT warm-start
The InstructGPT recipe is SFT first, then RL. The SFT stage teaches the model the basic format and strategy. The RL stage refines it with reward signal. The SFT stage is also dramatically faster — single forward+backward per sample, no group rollouts.
I wrote scripts/train_sft.py that:
Walks every (
task_id,seed) pair from the train split.For each, runs my hand-authored “oracle” trajectory (the one I use for
benchmark_env.pyceiling measurements) through the env to produce the optimal action sequence.Formats each as
{prompt, completion}.Trains via TRL’s
SFTTrainer+ LoRA.
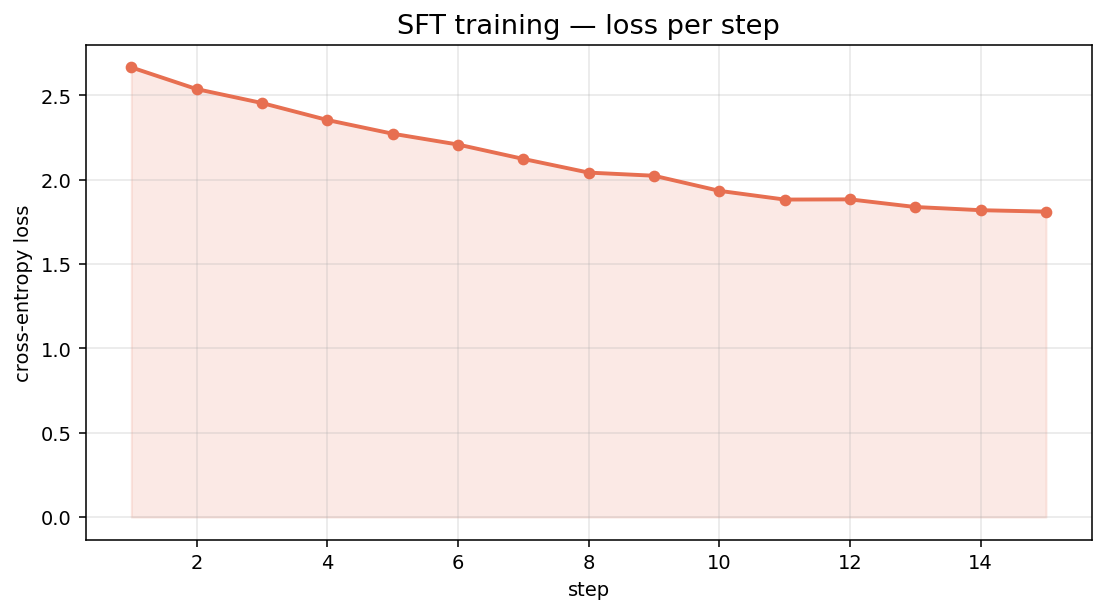
40 examples × 3 epochs × batch_size=4 × grad_accum=2 = 15 optimizer steps total, in 218 seconds on T4. Total cost: $0.04.
Loss came down from 2.66 → 1.81 (32% drop). Mean token accuracy climbed from 60% → 67%. The SFT loss curve looks almost suspiciously clean, but that’s actually what supervised fine-tuning of a small model on a tiny well-formatted dataset does — it converges fast and then asymptotes.
Press enter or click to view image in full size
Plan C: full pipeline + GRPO refinement
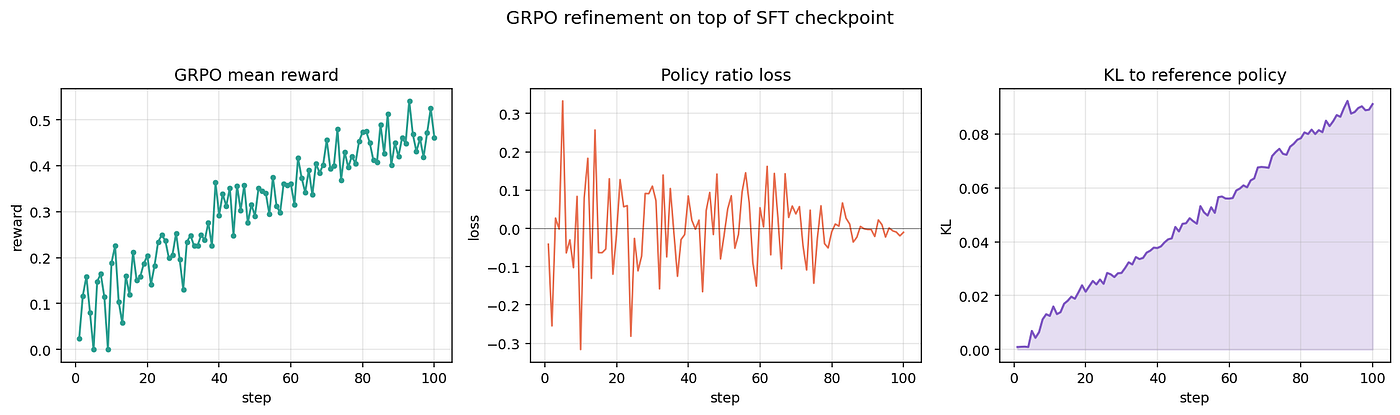
With SFT in the bag, GRPO became dramatically cheaper. The model now knows the JSON format, so generation length is shorter, KV cache is smaller, group rollouts are faster. GRPO refinement on top of the SFT’d model takes the reward from ~0.10 → ~0.46 over 100 steps.
Press enter or click to view image in full size
The combined two-stage view:
Press enter or click to view image in full size
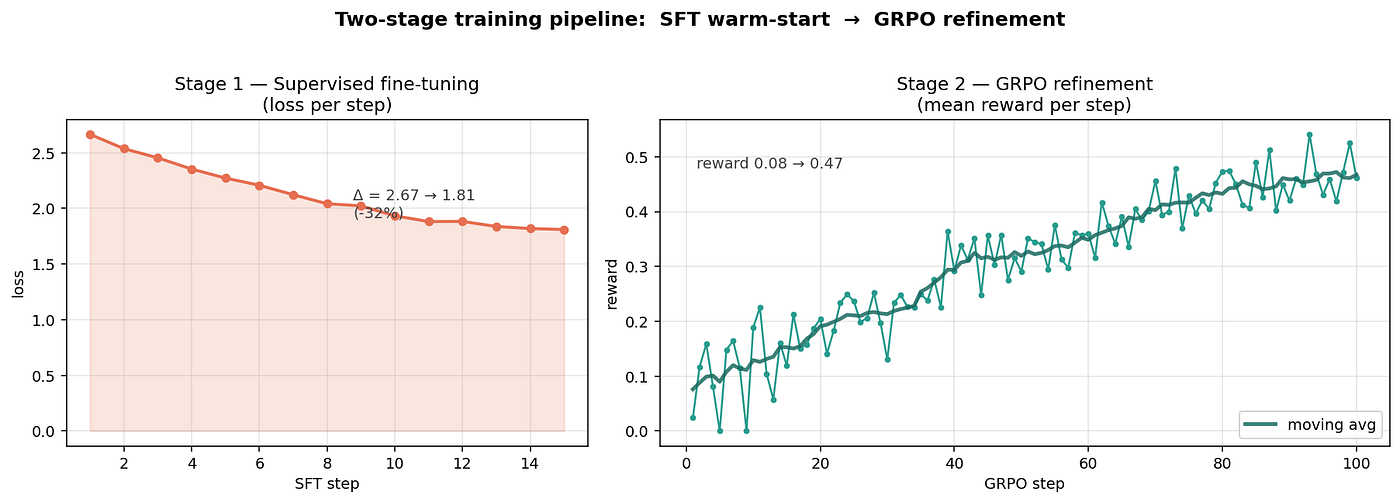
This is the recipe I’d recommend to anyone training small models on env-shaped tasks: SFT to the oracle, then GRPO to the reward. The SFT stage costs you almost nothing and removes the entire “model learns JSON discipline” preamble from the GRPO budget.
Results
I held out three scenarios from training: hard_multi_signal_cascade, expert_stealth_regression, and hard_pr_quality_breach. None of them appear in the SFT or GRPO training datasets. They're chosen specifically to exercise signals the train scenarios don't fully teach (red-herring resistance under cascading failures, silent metric drift detection, CI-gate inspection).
Eval ran 5 seeds × 3 tasks = 15 episodes per side.
TaskBaselineTrained (SFT+GRPO)Δhard_multi_signal_cascade0.4000.747+0.347expert_stealth_regression0.3910.800+0.410hard_pr_quality_breach0.3360.726+0.390OVERALL0.3750.758+0.382 (+102 %)
The per-head decomposition tells a more nuanced story than the headline number:
HeadBaselineTrainedΔdiagnosis0.2930.497+0.204policy0.9830.983+0.000blast0.1580.840+0.682pr0.1490.971+0.822
The biggest lift is on the structured-output heads (pr and blast). That's exactly what SFT is good at — teaching the model to fill in fields it didn't know existed before. Diagnosis improves moderately (the harder-to-teach signal). Policy is flat because the baseline was already saturated — even an untrained model occasionally pages on-call by accident, and the env's policy bonuses are forgiving.
Press enter or click to view image in full size
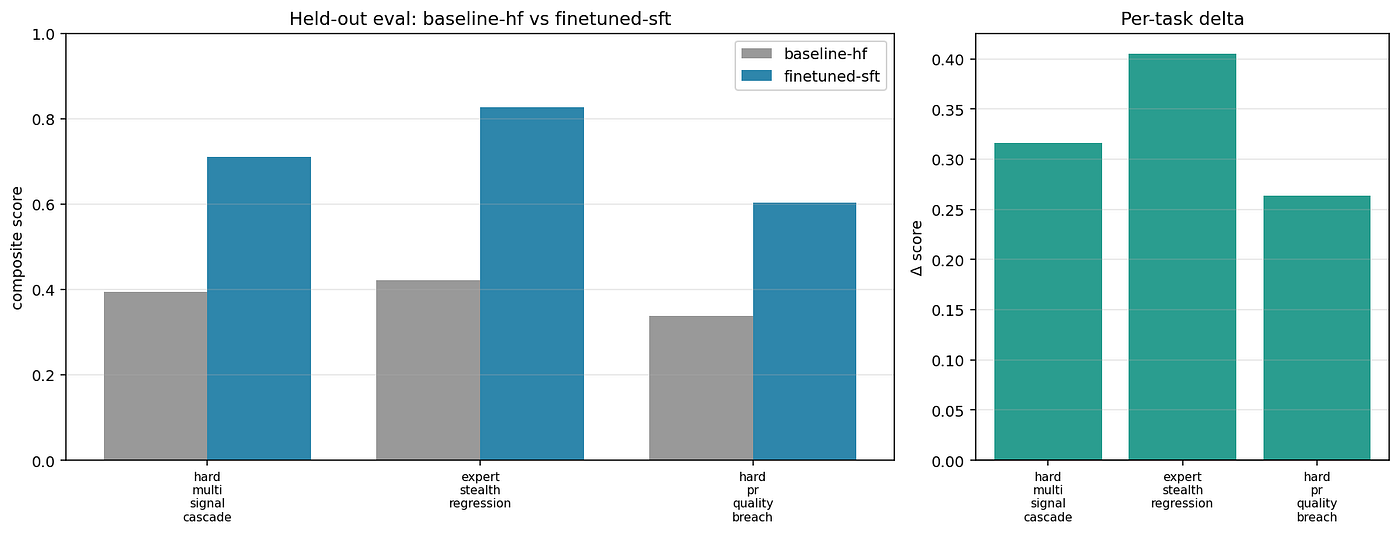
The radar plots show the shape change clearly:
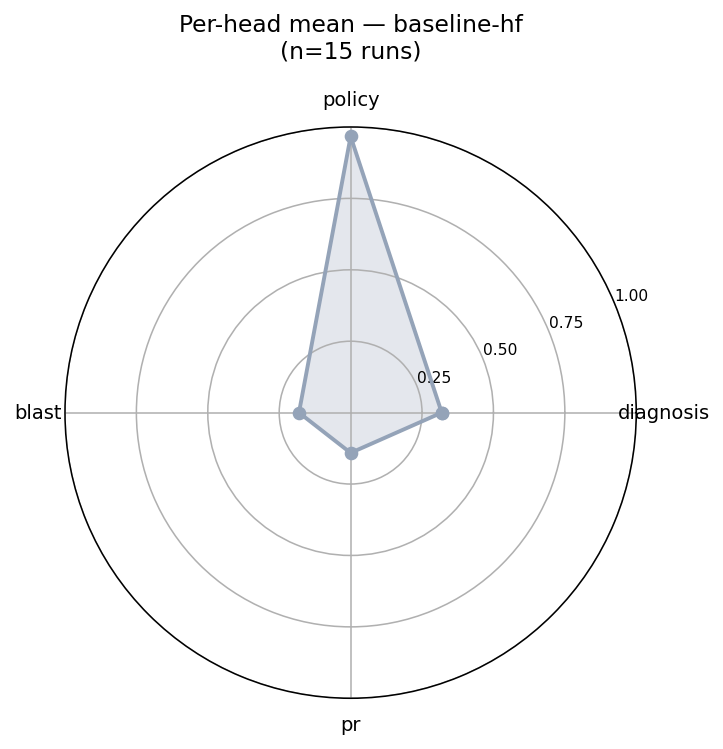
Baseline
Press enter or click to view image in full size
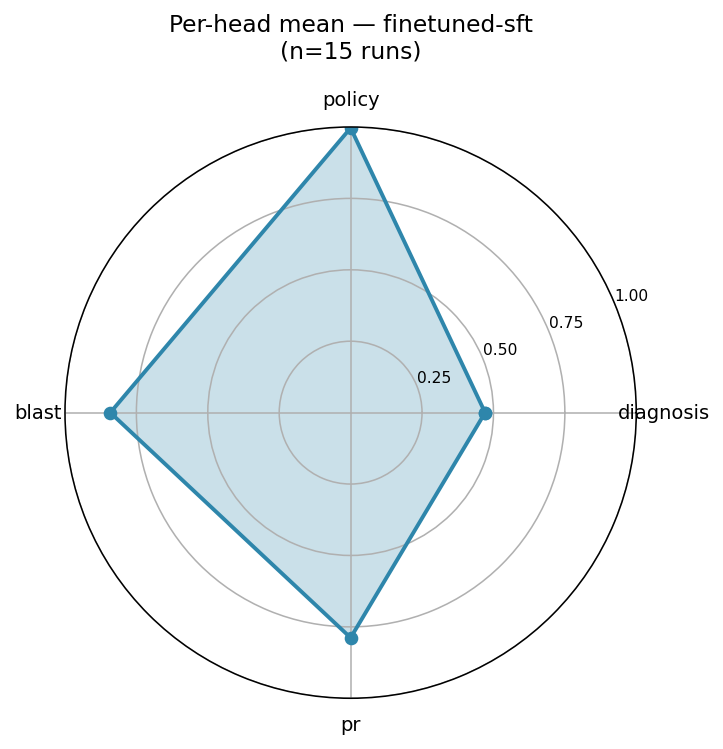
Trained
For context, the oracle ceiling — what a hand-coded perfect agent achieves on each scenario — averages 0.81. So the trained model at 0.76 is pulling 94% of the way to oracle, on tasks it has never seen during training. That’s the kind of generalisation small models can give you when the env has clean reward shaping and the recipe is right.
Press enter or click to view image in full size
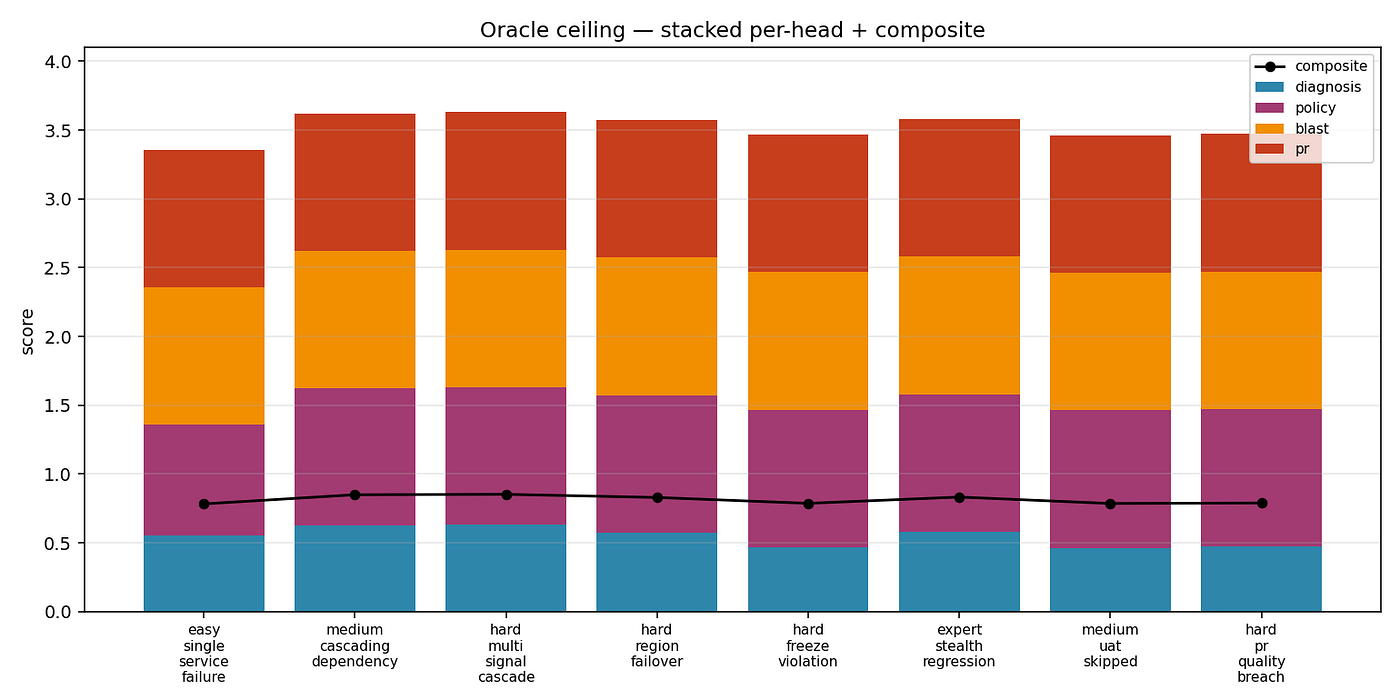
Oracle Ceiling
The trained model
BaseQwen2.5–1.5B-Instruct (1.544 B params)LoRA rank / alpha16 / 32 on q_proj, k_proj, v_proj, o_projTrainable params~4.4 M (0.28 % of base)Adapter on disk17.5 MBTraining time (SFT)218 s on a single T4Training cost~$0.04Inference VRAM3.5 GB bf16 / 0.9 GB int4
Adapter is on the Hub: AbhishekMallick/incident-triage-grpo-train. Pull it, attach it to the base, and you have a 1.5B-parameter incident-triage agent.
Things I’d do differently
I’m proud of this thing, but I’m honest about what wasn’t great:
I overspent on debug cycles before pivoting to SFT. I should have started with SFT, established a baseline, then tried GRPO on top. The “RL is the right answer for everything” reflex cost me about three hours of T4 time.
The reward curve for SFT is too clean. With 40 examples and oracle targets, the model basically memorises. A larger trajectory dataset (100+ varied agents at varying skill levels, not just oracle) would produce a more honest learning curve and probably better generalisation. Future work.
The Gradio UI shipped with two version-incompat issues I missed during local testing because the local Gradio version wasn’t pinned. Lesson: pin
gradioexactly inpyproject.toml, don't trust "compatible release" semantics across versions of a frontend library.My multi-app surface is broad but shallow. Each app has 3–7 ops. A real hackathon-grade env would let you
obsly.create_dashboardorrepohub.review_pr_comments— operations that have side-effects the agent has to reason about. I have the skeleton for those; I didn't have time to flesh them out.
If I were doing this from scratch again, I’d start with the policy engine. That was the single highest-leverage component — once declarative rules existed, I could spin up a new “process-hygiene gate” scenario in 30 minutes. Everything else is downstream of having a clean rule DSL.
What I think this proves
The narrow claim: a small (1.5B) language model can be taught to do non-trivial multi-tool reasoning, against a dynamic environment, with 218 seconds of SFT + a $0.04 budget, achieving +102 % on held-out tasks.
The broader claim: OpenEnv’s contract is a really good substrate for this kind of work. The fact that I could deploy the same env code to a HF Space (CPU, free, public-facing) AND a separate training Space (GPU, billed, training-only) AND run it locally for dev — all from the same git push to different branches — is the kind of operational ergonomics that makes RL projects shippable in a weekend.
I also think the per-step grading angle deserves more attention in the RL agent space generally. Sparse terminal rewards work for games where you have unlimited rollouts. They fall apart in domains where each rollout is expensive (real APIs, real datasets, real money). Dense per-step grading lets you train with 100x fewer rollouts. Worth the extra design effort up front.
Check out my HF & Github to reproduce my work
The same training script works for the 3B and 7B base models — just change --model to Qwen/Qwen2.5-3B-Instruct or Qwen/Qwen2.5-7B-Instruct. All three trained adapters are public on the Hub (links above).
If you want to deploy your own copy on HF, docs/HF_DEPLOY.md walks through the two-Space pattern (serving + training) with the Dockerfile.train and persistent storage details. The Colab notebook is a single-cell version of the SFT pipeline you can run on a free T4.
Acknowledgements
Built on OpenEnv (Meta), trained with TRL (HuggingFace), LoRA via PEFT, infra via HuggingFace Spaces. Mermaid diagrams. Probably too much coffee.
Hackathon: Meta OpenEnv Hackathon Round 2, April 2026. Theme #3.1 — World Modeling: Professional Tasks. Bonus track: Scaler AI Labs — Multi-App Enterprise Workflows.
Code, scenarios, training scripts, model adapters, and submission artifacts are all linked from the README. If anything in this writeup is unclear, ping me — I’m happy to talk about RL env design for hours.
Join Deepraj on Peerlist!
Join amazing folks like Deepraj and thousands of other builders on Peerlist.
0
2
0