Unifying the wearable data
We must imagine Sisyphus happy
Wearable data from multiple sources is a mess - that much I hope we can agree on based on the issues discussed in my last article. The problem now is what to do about it? How can we go from idiosyncratic, separate data structures into a unified data model that will be both elegant and efficient?
How did we get here?
This issue is not apropo of nothing - those are considerations that anyone working with wearable data, and issues I've faced with my team when trying to build a data framework that would be a future basis for such integrations. Solving this was our goal when starting the Open Wearables platform
Having such a unified data structure would be a gigantic step in unlocking the possibility to funnel data from multiple sources into one space, saving a lot of time for data engineers building such a structure each time anew when setting up new data warehouses.
Unified data definition
Of course, this is easier said than done, developing such a model is a big endeavour, itself being only one of the elements involved in constructing a comprehensive wearable data brokering service. While building the raw integrations was going well (with minor hiccups you expect during such endeavours - patchy documentation, limited access, the usual), the data problem still loomed over us. What will be the structure that will be the core framework for our data?
The issues to consider were as follow:
The data recorded is of different types - we face both standard datapoint as well as time series data (observations where not only values are important, but also their organisation)
The time series data will be a significant part of the held records and we need to minimise the resources - both memory and computational - needed to work with them
The data needs to be analytically optimised first and foremost, as simply storing it is not a goal - we need a structure that will work well with ML/AI and other fancy statistical methods
We need a clear separation between the potentially multiple users, as well as multiple sources, sometimes with multiple sources per one user (think a smart watch and a phone)
The data structure needs to be easy to expand - we won't be able to support all the providers from the get go, and we need space to add new types of series, events etc. as new use cases appear
The resulting structure cannot be opaque and convoluted - after all, we knew too well the experience of a dev struggling to get a grip of a poorly documented or unwieldy project
This is a daunting list, and to no surprise - if it was easy, the solution would already be there.
After multiple iterations and brainstorming sessions, we still had a problem persisting due to the conflict between two approaches to weaving data storage - transactional (think classic databases supporting live platforms and apps) and analytical (data warehousing, optimised for storage and calculation, but not lean and efficient).
The compromise between analytis and operations
The unified structure we arrived at had a distinct touch of both of those approaches, as we realised that a compromise would only result in sacrificing important aspects of both storage structures. The unified data model for Open Wearables is more of an amalgamation than a compromise - we decided to hold onto the unification of data structures, but with two distinctive types, relevant to the specificity of data stored. Thus, we defined two core concepts:
Records - meaning any singular events, with multiple descriptors and aggregate values that can be defined for the whole period of the event.
Series - classic time series, consisting of dense data points, ordered in time
The user descriptors are a specific case - we knew that some features will be hardly changing (for example, birthday - used for age), but some can be slow-changing - not enough to share space with fully fledged time series, but enough to clutter the events. This led us to temporarily store those as time series as well, but in future releases, we consider building a dedicated BodyStats structure that could store those as daily snapshots.
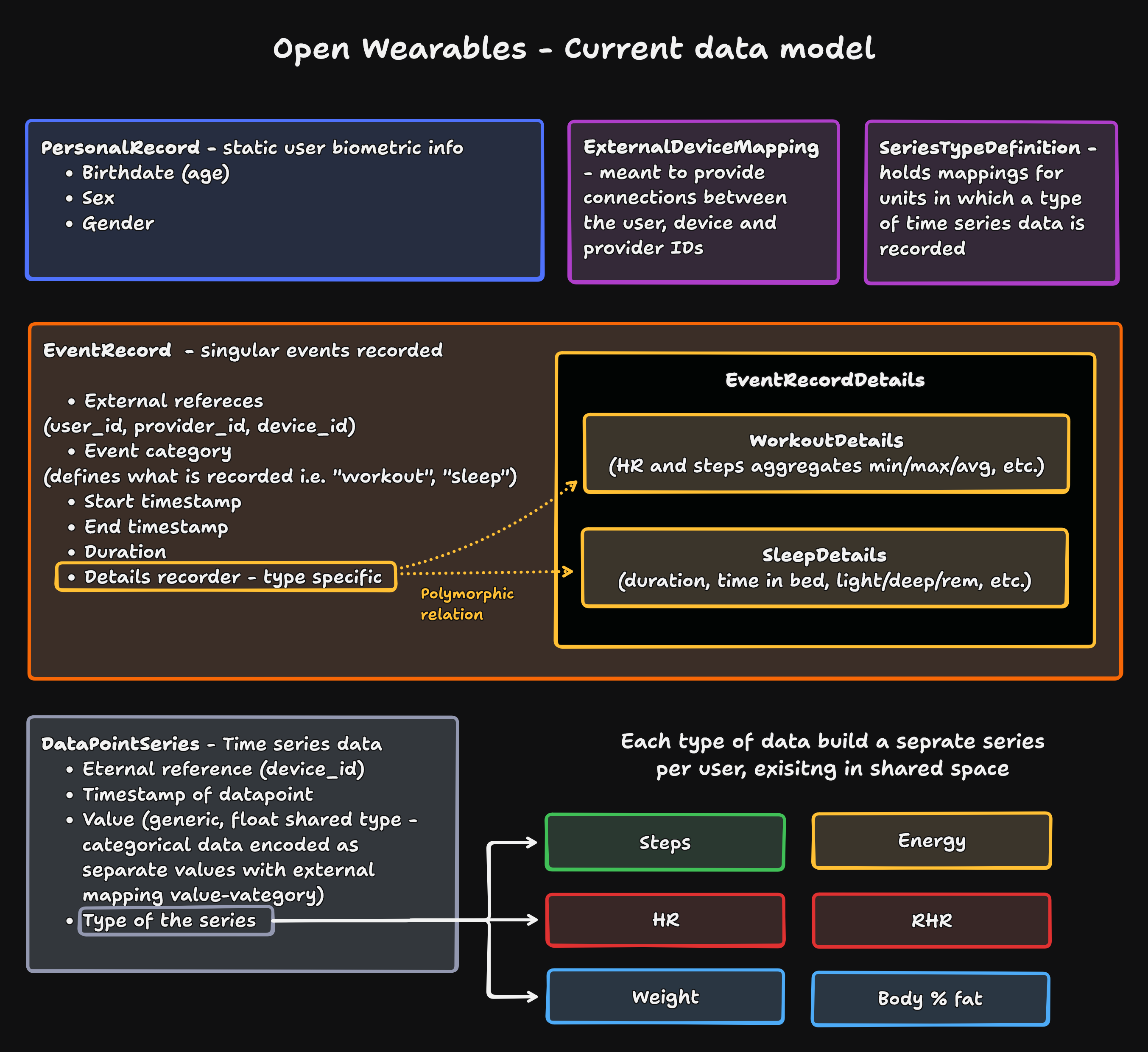
The general outline of the unified data model that solves the core issues defined for wearable data
The resulting structure, as you can see, is relying heavily on uniformity and polymorphism - we want our events to be generic, but be defined depending on the details. After all, all events will share fields such as start/end date, or relations to the user, but what decides if we work with workout data or sleep is the details - the aggregates that describe the event.
Similarly, time series data will be generally uniform - every data point has a value, a timestamp, and a reference to what device recorded it. But there is a catch here- not all time series are made equal. You can have a time series consisting of categorical or numeric data (and numeric can be further subdivided into integer or float values, for example).
Such a structure would solve the problems we defined at the beginning, forming a multipurpose data model at the core of any wearable data-driven system.
Reality versus the ideal approach
This model was our goal - we defined it as a structure that we want to arrive at, but the hard reality is that every solution needs to start somewhere. Adapting the theoretical approach to fit the realities on the ground is almost as important as the core idea itself.
The approach we took was to build a solid core, the essence of what we defined in the unified data model, and leave space for future extensions. This way, we not only gain the ability to start much quicker, but also can, in the future, define this model at different levels of complexity, which can be scaled up, depending on the target project.
For the base iteration, we made a concession - faced with the vision of building separate tables for each time series, some of them practically identical, but with different names (a hard warehousing approach), we agreed to a bit of excess data, to preserve a single table approach. Time series in our model are supported further with type - defining whether this is heart rate data or steps data, and the values are always treated as floats. This can result in memory heavy structure, but does not lose any information - categorical data can be encoded as separate values with supporting mappings, and numerical values are cast into the widest (reasonably) possible type. To offset those issues, we introduced intermediary tables, such as one for external IDs around matching user to device to provider. There is also one to match series type to a unit name abbreviation, in which the series is stored. This way, there is no relying on assumptions as to what is the exact data format is, and no data bloat due to storing units per each datapoint.
This way, we arrived at the current data model used in the first release of our Open Wearables platform - lean enough not to block the project progress, but robust enough to answer the defined issues, and what is most important, able to scale up and be extended with simple migrations.
We have the data - what now?
With all this discussed, we have a solid basis, but still, the data is only stored. While this is crucial and a prerequisite, it does not provide any additional insight or value. This will be a topic for a future article - after all, we want to do something with all this data, and data model, while important, is only means to an end.
Join Filip on Peerlist!
Join amazing folks like Filip and thousands of other builders on Peerlist.
1
8
0