Wearable data swamp
The murky pond of tangled data points nobody wants to touch (and how we are solving that)
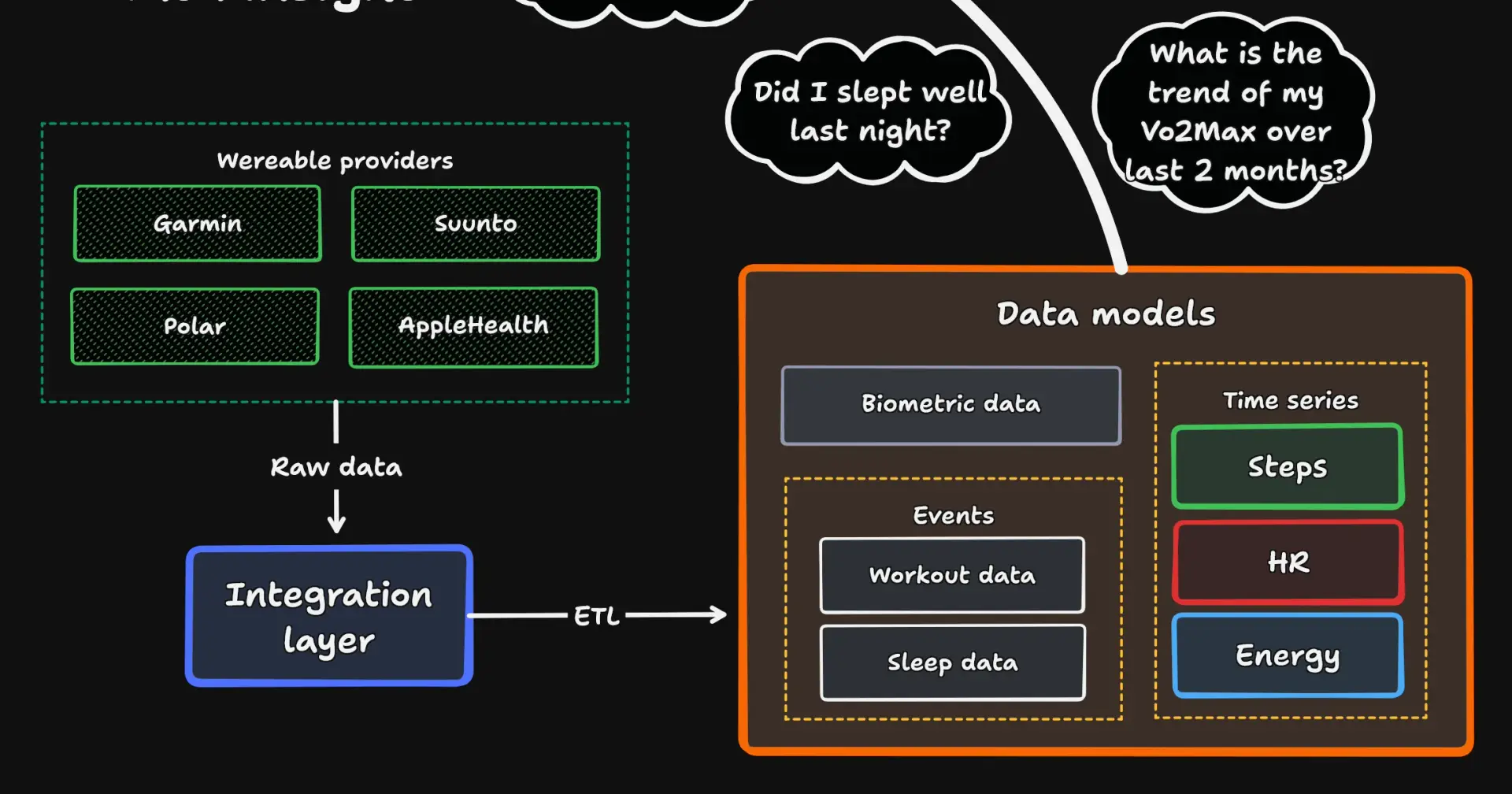
We live in the data overload era - all our devices generate new records, we get multitude of notifications, see dashboard upon dashboards, but rarely do we get anything from it. All those potentially invaluable datapoints, describing details of our life are drowning in a data swamp - little care is paid to how it should be stored for any analytical usage, not mentioning ML or AI. What is worse, this sludge is highly demarcated to make the problem worse - our swamp is in fact multiple murky ponds, each with its own storage and data handling logic. Anyone who tried to integrate with more than one wearable data provider can easily attest to that.
My goal here is to show that not only we can do better, but also discuss one possible approach to that, via a unified data model, built with multiple datatypes in mind.
Sifting through the mess - Nature of the problem
If you are not familiar with wearable data this issue might surprise you. After all, how many ways are there to record data? Is this really a big problem - surely, the end user won’t be running around with 5 different smart watches on his hand. Why do we need to bother with this issue anyway?
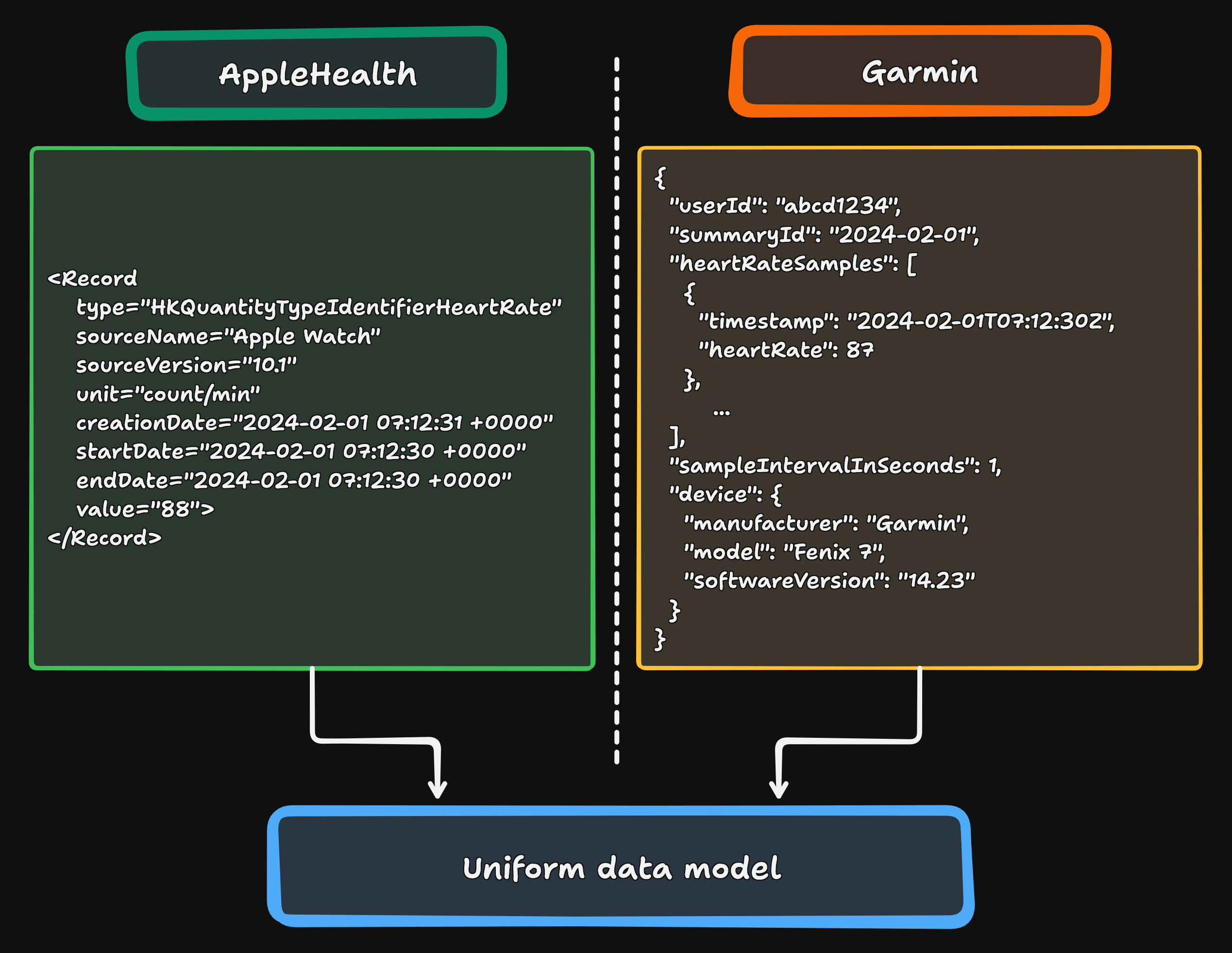
You can see here how example data fetched even from leading providers differ widely
Well, surprisingly, it is. Take into account that we are looking at multiple providers, each with their own data structures, their own communication protocols and API, and often their own proprietary devices with different sensors and algorithms - all of this unregulated in any way and the questions should answer themselves.
Take a look at the Comparison above - between Apple Health and Garmin. Not only the structure is wildly different, but the data acquisition as well. As of now, AppleHealth allows for data exports via their service as an XML file, or directly through a mobile app using their SDK, while Garmin offers an API. This alone makes integrating those providers two separate and daunting tasks, before even thinking about unifying data recorded by both providers.
The simple answer doesn't cut it - "just normalize it". Yes, but how? The differences are not simply in notation or data units. This is a deep and fundamental divide in how the data is stored, with actual datapoints buried inside idiosyncratic structures. You could extract each one by hand, with tailor-made scripts, but this brings us to the beginning - the workload is often discouraging.
The last line of defence persists - do we need to support multiple providers? The short answer is, that if you want as wide a user base as possible, then yes - no service will currently cover most of the market, as the users are split across multiple platforms. Selecting only one type of device locks you out of potential users and enforces a vendor lock.
Unifying the data - the road ahead
The approach to this that I see, and my team shares, was straightforward - build a platform that offers multiple integrations, supports a full import and processing pipeline, and ends with a unified data model, ready for serving and usage.
In essence, this would mean that we need a platform that provides:
Uniformity - in essence, handling similar datatypes in similar ways, storing that in a shared data structure
Modularity - the proposed structure must be easily extendible, since the market is fast-growing and we cannot hope to cover all the data providers at once
Compressibility - since this is a data aggregation task, the volume of data is an issue in itself, and avoiding unnecessary bloat is crucial
Efficiency - we plan to use the data, not just store it, so any operation on the data structures must be as handy and as optimal as possible
Of course, this is easier said than done. We spent the last month of 2025 hammering away at this problem with the Open Wearables platform, and we are still at the beginning of our journey, but even with a base structure, we already see how beneficial this can be for the wereables data driven project.
While the data model itself is a separate topic worth a dedicated article, I want to leave you with this - there is tremendous value locked inside the wearable data that is currently being underused due to a lack of a proper and unified way of data handling. Ignoring this is to ignore a number of possibilities, only because there is no clear way forward through the murky data swamp.
Join Filip on Peerlist!
Join amazing folks like Filip and thousands of other builders on Peerlist.
1
9
0