Stage gate loops
Why agent verification needs to move from the end to every transition

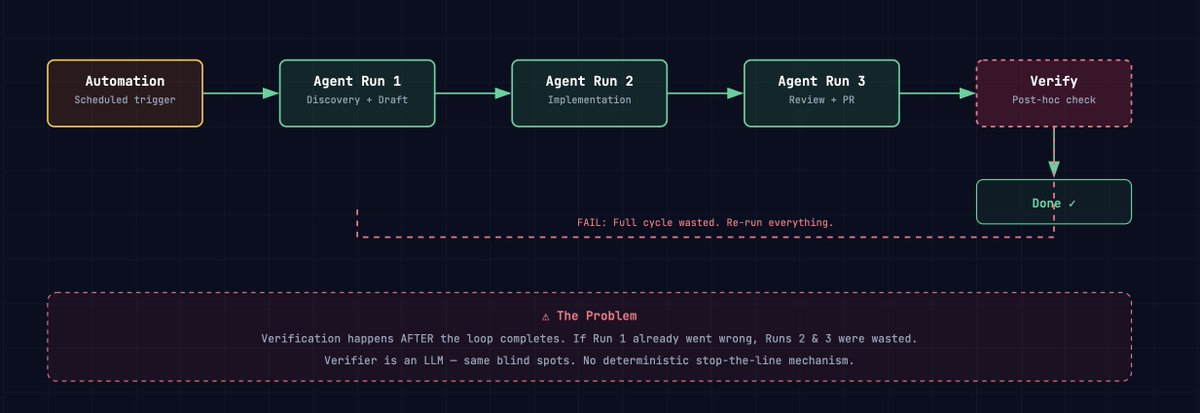
The way we build agent systems has shifted. We no longer prompt them turn by turn. We design systems that prompt them: scheduled automations, isolated worktrees, reusable skills, sub-agent hierarchies. The work of an agent engineer is increasingly the work of designing loops.
But there is a structural flaw in how these loops verify their output. Across the major agent platforms, verification happens at the end. The loop runs, the loop finishes, then a review step checks whether any of it was worth doing. If the review catches a failure, the entire cycle is wasted. If it doesn't - and often it doesn't, because the reviewing model shares the same architecture and blind spots as the model that produced the output - the failure ships.
This is not a new problem. It is a recurring pattern in engineering, and we have solved it before.
The borrowed wisdom
Stop the line
Toyota's Andon cord is one of the most studied quality-control mechanisms in industrial history [1]. A worker on the production line spots a defect and pulls the cord. The line stops. The problem is fixed at the source before the car moves to the next station. Quality is not inspected in at the end of the assembly line. It is enforced at every station.
The Andon system is part of Jidoka, or "automation with a human touch" - one of the two pillars of the Toyota Production System [2]. The principle is simple but radical: anyone can stop the line. The cost of stopping is lower than the cost of shipping a defect downstream, where it becomes exponentially more expensive to fix.
Test first, code second
Test-driven development applies the same logic to software. The cycle is well-documented: write a failing test, make it pass, clean up the code, repeat [3]. The test is written before the code. Passing the test is the gate. You don't write all the code and then write all the tests at the end. The verification is structural, not post-hoc.
Empirical research on TDD shows mixed but directionally positive results. A 2013 meta-analysis of 27 studies found a small positive effect on external quality, with larger gains in industrial settings [4]. The mechanism that matters is not the test-first ordering itself but the discipline of small, verified steps - what a 2017 study described as "small, uniform development steps" rather than the test-first ordering alone [5].
Quality gates in CI/CD
Continuous integration brought automated verification to every change. Every commit triggers an automated build and test suite. Failures surface immediately [6]. The CI pipeline is a series of gates: compile, unit test, integration test, static analysis, deploy to staging. Fail any gate, the pipeline stops. The change never reaches production.
Gates are deterministic. A test suite returns pass or fail. A compiler returns errors or it doesn't. No opinion, no confidence score, no "seems right." The gate is a contract. The artifact satisfies it or it doesn't.
The gap in agent systems
Agent systems have not adopted this pattern. The dominant architecture across platforms - scheduled automations, isolated worktrees, reusable skills, sub-agent hierarchies - treats verification as a final step. A sub-agent reviews the output of the main agent. The review is itself an LLM call, subject to the same failure modes as the original generation.
The research literature on LLM-based evaluation has documented this problem extensively. LLM-as-judge approaches show systematic biases: a preference for longer outputs, sensitivity to prompt ordering, and a tendency to agree with outputs that share the same model architecture [7]. The model that writes the code is, as the saying goes, too nice grading its own homework. But the model grading it is an LLM too.
There are three compounding costs when verification comes at the end:
Token waste - If an early stage of a multi-step agent run produces output that is fundamentally wrong, the remaining stages still execute.
Self-grading blindness - When the reviewing agent is an LLM, it has the same failure modes as the generating agent. Both models share the same architectural constraints: they hallucinate, they miss edge cases, they are overconfident on incorrect outputs. Swapping one LLM for another doesn't solve this.
No breakpoints- In a standard agent loop, there is no mechanism to stop mid-execution. If stage 2 of 5 produces garbage, stages 3, 4, and 5 still run. The loop has momentum but no brakes.
Introducing "Stage gate loops"
The fix is to move verification from the end to every transition. Break the agent's work into distinct runs. After each run, try inserting a deterministic eval gate preferably not an LLM evaluating output, but a tool returning pass or fail. A schema validator. A test suite. A type checker. A build step. A CI status check.
Pass the gate, proceed to the next run. Fail the gate, stop. Log the failure. Surface the exact breakpoint. Retry from that stage.
The structure looks like this:
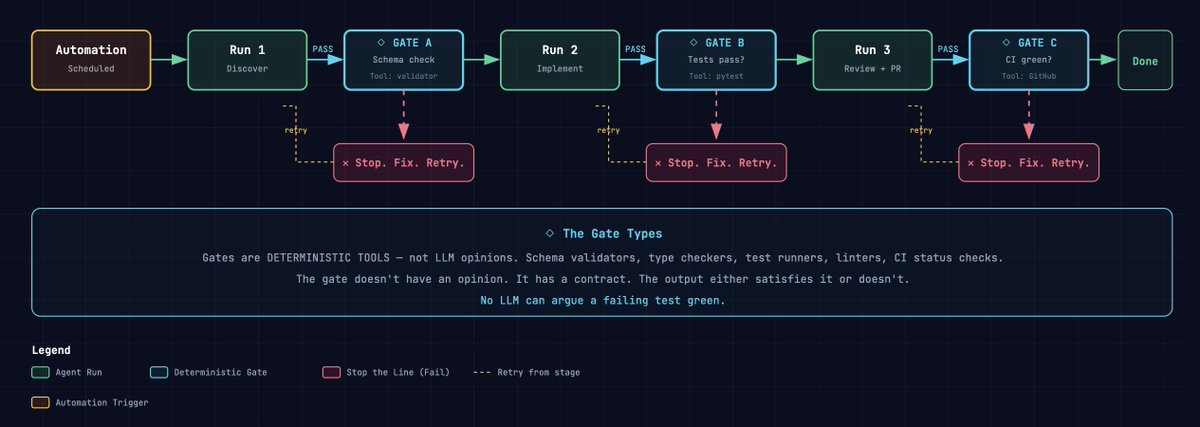
Any gate fails, the loop stops. The failure is logged with the exact output that caused it. The loop retries from that stage with the fix, not from the beginning. Runs downstream of the failure never execute, so tokens are not wasted on doomed work.
Why deterministic gates are preferable ?
A deterministic gate is a tool, not a model. A schema validator cannot be talked into accepting invalid JSON. A type checker cannot be persuaded that a string is an integer. A test runner returning a non-zero exit code cannot be argued into green. The gate has no opinion. It has a contract.
This is the crucial distinction. LLM-based verification asks "does this seem right?" Deterministic verification asks "does this pass?" The difference is between probabilistic judgment and binary truth. In contexts where correctness matters - code generation, data transformation, configuration management - probabilistic judgment is not enough.
Building it: experience from production agent systems
I arrived at this while trying to build my own agent called "Groot" over Hermes. The system I built orchestrated multiple autonomous agents that handle everything from research to drafting to review to publication. The agents run on schedules. They spawn sub-agents. They read and write to shared state. For a long time, the verification model was standard: the agent completed its full run, then a separate review step checked the output.
The failure mode was consistent and expensive. An agent would spend seven minutes on a multi-stage task - discovery, drafting, review, delivery - and the review step at the end would catch that the draft failed a basic schema check at stage two. Six minutes of downstream work, gone. Tokens burned. And the review step itself wasn't reliable: roughly a third of the time, it missed failures that a deterministic tool would have caught.
The fix was to insert gates between stages. After discovery, a rule check: is the finding concrete enough to act on? After drafting, a schema validator: does the output conform to the expected structure? After review, a test suite: do the integration tests pass? Each gate is a tool call, not an LLM call.
The token savings were immediate. A run that previously consumed 12,000 tokens end-to-end now stops at 3,000 if it fails at stage two. More importantly, the failures that do occur are inspectable. The gate that failed tells you exactly what went wrong and what output triggered it. You don't replay the whole run to debug. You look at the breakpoint.
Now, Groot has a decided skills called "grooting" inspired by stage gate loops. It runs a structured execution framework: define a goal, write binary pass/fail evals, break the work into discrete tasks, execute each task, then run every eval against the output. If all evals pass, the work is done. If any eval fails, the agent reflects on the failure and retries — but only from the failing stage, not from the beginning.
The evals are the gates. And they are as deterministic as possible where it matters: schema conformance, link validity, test passage, exit codes. When a cron job runs this framework and a task fails at eval three, the agent doesn't burn tokens on tasks four through seven. It stops at the breakpoint, fixes what broke, and resumes. The result was a measurable drop in cron failure rates - jobs that previously failed silently or burned through their token budget on doomed runs now fail fast and self-correct. The framework turned a loop that hoped into a loop that verified.
The system still uses LLMs for the work that LLMs are good at: generation, summarization, reasoning about ambiguous inputs. But the verification layers are designed as deterministic as possible.
Gate design is the new bottleneck
The trade-off is real. Moving verification to the gates means gate design becomes the critical skill.
Bad gates pass everything and catch nothing. A schema validator that accepts any shape, a test suite with no assertions, a lint step with every rule disabled - these are not gates. They are decorations.
Overly strict gates stall everything. A gate that rejects valid output because of an edge case in the validation rule creates a different kind of waste: the loop never progresses because the gate is too rigid.
Good gate design requires understanding the failure modes of the system. What kinds of errors does this agent actually make? What would a false negative look like at this stage? What would a false positive cost? The answers are specific to the domain, the agent, and the task.
There is no general-purpose gate. There are only gates designed for specific failure modes by someone who understands the work. This is harder than writing a prompt. But it compounds. A well-designed gate catches a class of errors forever. A well-crafted prompt catches errors once, if you're paying attention.
Where gates don't apply
Not every agent task can be gated very deterministically. When the output is prose, creative strategy, architectural judgment, or ambiguous-input classification, there is no mechanical check for correctness. A schema validator cannot tell you whether a blog post is compelling. A test suite cannot evaluate whether a system design is coherent. For these tasks, the semantic verification layer necessarily remains probabilistic.
This is not a weakness of the stage gate approach. It is an acknowledgment of its boundary. The goal is not to replace every instance of LLM-based review with a deterministic check. It is to push the boundary as far out as it will go, and reserve probabilistic review for the remainder.
In practice, this means gates handle the structural layer: format compliance, link integrity, schema conformance, test passage, type safety, lint rules. The semantic layer - tone, argument quality, strategic fit - still relies on review, whether by a human or a differently-prompted model. But by the time that review happens, the structural failures have already been caught. The reviewer is not wasting attention on JSON that doesn't parse or tests that don't pass. They are evaluating what matters: whether the output is good, not whether it is well-formed.
This is the same trade-off that CI/CD pipelines make. A CI pipeline does not prove that your code is correct. It proves that it compiles, passes tests, and conforms to lint rules. Correctness is a higher bar, and it remains a human responsibility. The pipeline just makes sure you are not spending human attention on failures a machine can catch.
Agent stage gates do the same thing. They do not guarantee quality. They eliminate the class of failures that are cheap to detect and expensive to miss.
The deeper pattern
Stage gate loops are not an invention. They are a recombination of ideas that have worked in other domains for decades. Toyota's Andon cord. TDD's red-green-refactor. CI/CD's pipeline gates. NASA's mission phase reviews [8]. The common thread is the same: quality is built in at every transition, not inspected in at the end.
What is new is applying this pattern to agent systems, where the dominant architecture has treated verification as a post-hoc step performed by the same kind of model that produced the output. The substitution of deterministic tools for LLM-based review is the key move. A schema validator is not smarter than an LLM. But it is more reliable at the specific thing it checks.
The loop engineering paradigm has given us automations, worktrees, skills, connectors, and sub-agents. These are the building blocks of autonomous agent systems. What they lack is gates - deterministic checkpoints that stop the line when something breaks, before the failure cascades downstream.
Gates make agent loops trustworthy without requiring constant human attention. They don't guarantee correctness. They guarantee that known failure modes are caught at the point of origin, not at the point of delivery. That is enough to change the economics of running agents at scale.
References
[1] Ohno, T. (1988). Toyota Production System: Beyond Large-Scale Production. Productivity Press.
[2] Liker, J. K. (2004). The Toyota Way: 14 Management Principles from the World's Greatest Manufacturer. McGraw-Hill.
[3] Beck, K. (2003). Test-Driven Development: By Example. Addison-Wesley.
[4] Rafique, Y. & Mišić, V. B. (2013). "The Effects of Test-Driven Development on External Quality and Productivity: A Meta-Analysis." IEEE Transactions on Software Engineering, 39(6), 835-856.
[5] Fucci, D., Erdogmus, H., Turhan, B., Oivo, M., & Juristo, N. (2017). "A Dissection of the Test-Driven Development Process: Does It Really Matter to Test-First or to Test-Last?" IEEE Transactions on Software Engineering, 43(7), 597-614.
[6] Fowler, M. (2006). "Continuous Integration." martinfowler.com
[7] Zheng, L., Chiang, W. L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., ... & Stoica, I. (2023). "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena." NeurIPS 2023.
[8] NASA. (2004). NASA Software Safety Guidebook. NASA-GB-8719.13.
Join Gaurav on Peerlist!
Join amazing folks like Gaurav and thousands of other builders on Peerlist.
0
0
0