The engineering of language
From manual craft to automated optimization of prompts
This article provides a comprehensive analysis of the contemporary state of prompt engineering, moving beyond the anecdotal to a formal, structured framework. The high failure rate of automated and AI-generated prompts is a systemic issue rooted in the inherent non-determinism of large language models (LLMs) and the critical challenges of hallucination and bias. This article identifies these systemic failures and demonstrates that they are not isolated problems but rather the result of a fundamental misalignment between traditional software development practices and the unique nature of generative AI. To address this, a multi-layered taxonomy is proposed to categorize prompt engineering techniques, drawing from academic research and practical applications to establish a clear hierarchy from foundational principles to advanced methodologies. Finally, this article presents a detailed case study on Vertex AI, explaining its methodological advantage through its Automatic Prompt Optimization (APO) framework and comparing its capabilities against leading competitors. The analysis concludes that the future of successful generative AI deployment lies in a shift from "prompt crafting" to a systematic, iterative, and data-driven engineering discipline.
The unpredictability of Generative AI and the imperative for automated prompt optimization
a) The new bottleneck in software development: The recent rapid increase of large language models has democratized access to unprecedented computational power, enabling the creation of applications that can generate human-like text, images, and code with remarkable fluency. Yet, this explosive growth has simultaneously created a new, non-traditional bottleneck in the development lifecycle: the ‘prompt.’ Unlike traditional software, where code provides deterministic instructions that predictably transform well-defined inputs, prompts are inputs that seek to control and guide inherently non-deterministic systems. This represents a profound shift in software development, a challenge for which most teams are ill-equipped. The prevailing development approach often involves ‘spot-checking’ or relying on few challenges to gauge performance, a process that would be deemed inadequate for traditional software and is woefully insufficient for the dynamic and unpredictable nature of generative AI. The failure to treat prompt development as a rigorous engineering discipline, one that requires proper testing, systematic evaluation, and continuous refinement that leads to widespread, unscalable, and unreliable outcomes.
b) Problem statement: While the intuitive appeal of generative AI is undeniable but the promise to ‘type in a question, expect magic’, this intuitive approach is fundamentally flawed for enterprise and professional use cases. Organizations that adopt this mindset often find themselves ‘burning money on AI prompts that do not work’ because they lack a systematic, repeatable strategy for prompt design and validation. This article seeks to clarify this problem by providing a structured, evidence-based analysis that moves beyond anecdotal observations. The core objectives of this article are threefold: first, to diagnose the root causes behind the frequent failures of automated prompt generation; second, to propose and establish a formal taxonomy and hierarchy for prompt engineering techniques that can serve as a foundational framework for practitioners; and third, to evaluate the user's perception that Vertex AI is more accurate by examining its core methodologies and comparing them to leading competitors.
c) Roadmap: This sweet read is structured to provide a comprehensive, A-to-Z understanding of automated prompting. The analysis will first delve into the systemic failures of prompt generation, categorizing the challenges into technical, critical, and non-technical issues. Following this diagnostic section, the article will propose a formal taxonomy and hierarchy, synthesizing concepts from academic research and other disciplines to create a unified framework. Then you will read a case study on Automatic Prompt Optimization (APO), with a specific analysis of Vertex AI's approach and a detailed comparison against other platforms. And the final section will offer a set of guiding principles and a forward-looking conclusion on the future of this rapidly evolving field.
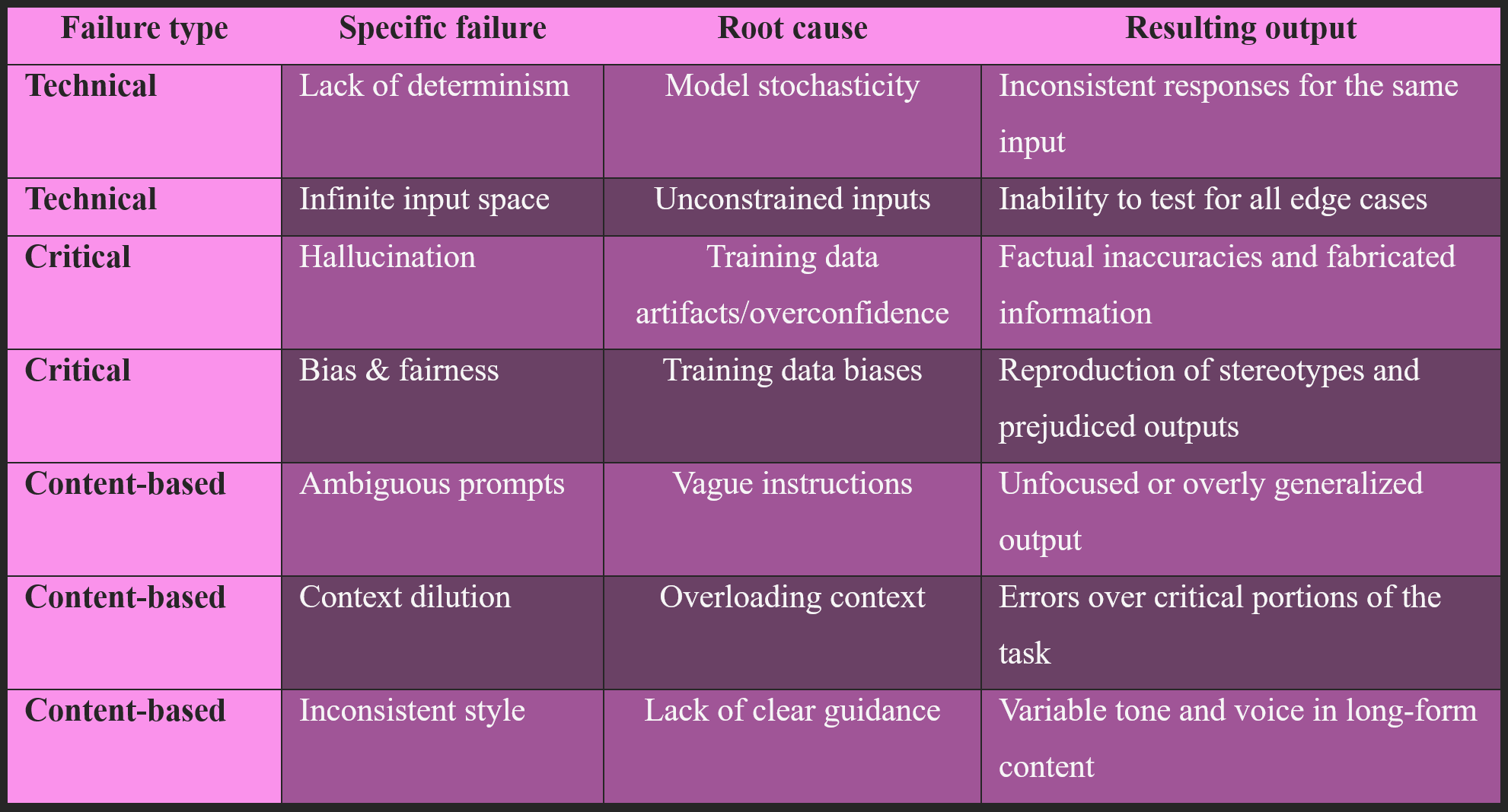
A root cause analysis of the systemic failures of automated prompting: The high failure rate of automated prompts is not an arbitrary phenomenon but a direct consequence of a set of identifiable, systemic challenges. These issues can be categorized into three primary domains: inherent technical limitations, critical content-based failures, and non-technical development misalignments.
a) Technical root causes are the non-determinism dilemma: At the heart of LLM unpredictability lies a fundamental technical reality: the stochastic nature of the models. Unlike a standard function that returns the same output for a given input, LLMs are inherently non-deterministic, meaning the same prompt can produce different, sometimes wildly disparate, results each time. This ‘lack of determinism’ makes traditional software testing methods, like spot-checking, completely insufficient. A test that passes one day may fail the next without any changes to the prompt or the underlying code. The second major technical challenge is the problem of the infinite input space. With traditional software, the range of inputs is constrained to well-known data types, such as integers, strings, or booleans. In contrast, the range of inputs for an LLM is virtually limitless, encompassing ‘the entirety of human language and thought’. This unbounded input space makes it impossible for developers to anticipate all potential user queries or edge cases, rendering comprehensive manual testing a non-starter and a primary reason why manual prompt engineering fails to scale.
b) Hallucination and bias are the critical failures: Beyond the technical hurdles of unpredictability, generative AI faces critical failures that can erode user trust and pose significant risks. The most prominent of these is hallucination, where the model generates confident but unfounded or incorrect statements. This is not a minor glitch but a fundamental property of how LLMs are trained; they are ‘created to provide a likely output based on prompts and training’ rather than to provide factual truth. Hallucinations can manifest in various ways, from subtle exaggerations and the fabrication of unverifiable information to entity errors and the creation of entirely fictitious events or academic citations. For example, a Sora-generated video of the Glenfinnan Viaduct incorrectly showed a second track and trains traveling on the right side of the track instead of the left, demonstrating this phenomenon in multimodal generation. Similarly, the model Galactica, designed for scientific paper generation, was withdrawn after it cited a fictitious paper by a real author, blurring the line between plausible-sounding output and factual accuracy. Second critical failure is bias and fairness. LLMs are trained on vast amounts of data from the internet, which inevitably contains societal biases. The models inadvertently learn and reproduce these biases, leading to “biased responses, affecting the fairness and impartiality of the information provided”. This was notably demonstrated when Google's Gemini AI was criticized for generating historically inaccurate images, raising serious questions about the model's training and validation procedures.
c) Non-technical & content-based failures: Many prompt failures can be attributed to non-technical issues stemming from the prompt's content and structure. The misinterpretation risk is a primary cause of poor output. A vague or general prompt, such as “explain climate change,” will produce an unfocused and overly generalized response. For a prompt to be effective, it must be specific, providing a clear roadmap for the model to follow. Another challenge is context dilution and inconsistency. Providing too much context in a single input can overwhelm the model, causing it to ‘confuse or err over critical portions’ and potentially ignore the most important instructions. Conversely, insufficient context leads to unhelpful or off-topic responses. Moreover, achieving a consistent tone or style is a major challenge, especially for long-form or collaborative content. Manual prompt engineering can be an iterative and time-consuming process, with developers often spending hours on ‘word choice’ debates that yield minimal results. The prevailing approach to prompt development incorrectly focuses on crafting the perfect initial prompt. This view is fundamentally flawed, as the core challenge of prompt engineering is not in the prompt itself, which is an unstable variable, but in the creation of a robust evaluation framework. A powerful body of evidence suggests that the primary work of prompt development is, in fact, test development. An effective prompt today may be worthless in a month as models change their behavior, but a well-designed test suite that defines the desired behavior will remain useful for the life of the system. This reframes the problem from a mystical art of finding the ‘magic phrase’ to a rigorous scientific discipline of defining and measuring success.
Furthermore, a significant realization is that the problems troubling generative AI non-determinism, bias, lack of test coverage, and performance degradation are not novel. They are the same challenges faced in traditional software engineering (e.g., regression testing), machine learning (e.g., model drift), and data analysis (e.g., data quality). The reason these issues are so acute in the context of LLMs is that many practitioners treat them as a ‘magical’ black box, ignoring decades of established best practices from adjacent fields. The solution, therefore, is not to invent a new paradigm but to apply these mature engineering principles to prompt development. The success of a platform or a company in this space hinges on its ability to re-frame the problem from a visionary art to a systematic science. The following table provides a taxonomy of these (automated prompts) failures, linking each type to its root cause and the resulting output.
A foundational taxonomy and hierarchy of prompt engineering: To move beyond the ad hoc nature of manual prompting, a structured framework is essential. This section proposes a comprehensive taxonomy and hierarchy that synthesizes principles from both academic research and behavioural science.
a) Foundational principles: Effective prompt design begins with a set of core principles that come before any specific technique. These principles are universal and applicable across all LLMs:
Clarity and specificity: The prompt must clearly define the task, audience, desired length, and format. Vague prompts lead to unfocused responses, while specific instructions lead to accurate and relevant outputs.
Context and background: Providing relevant information helps the model understand the intent and avoids unhelpful responses. This can include factual data, a specific source document, or the definition of key terms.
Instructions over constraints: It is generally more effective to tell the model what to do rather than what not to do. Positive, action-oriented instructions are typically more effective and flexible for the model to follow.
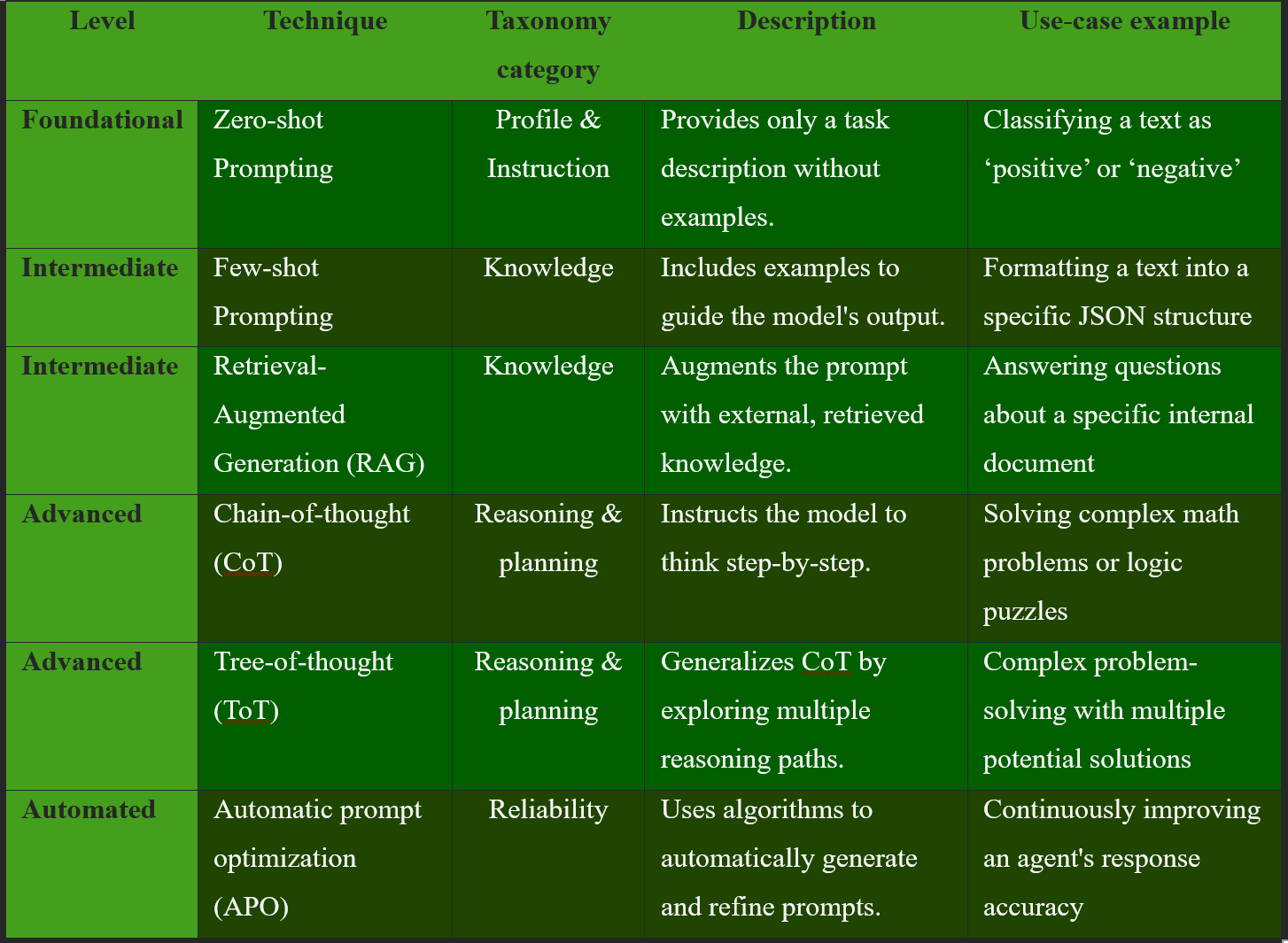
b) Taxonomy of prompting techniques: Any formal research & whitepaper proposes a comprehensive taxonomy that categorizes prompt engineering into four characteristic parts, providing a structured framework for understanding and systematically designing prompts:
Profile and instruction: This deals with the foundational framework for crafting a prompt. It includes basic zero-shot instructions and more nuanced persona-driven prompts that guide the model to adopt a specific voice or role.
Knowledge: This aspect is related to the external knowledge incorporated into the prompt. Techniques in this category include few-shot examples that demonstrate the desired behavior, as well as Retrieval-Augmented Generation (RAG), which dynamically retrieves relevant external documents and injects them into the prompt to provide up-to-date and specific information.
Reasoning and planning: This involves techniques that guide the LLM's internal thought process. The most prominent example is Chain-of-Thought (CoT) prompting, which instructs the model to break down a complex problem into a series of intermediate, logical steps before providing a final answer. This technique has been shown to be highly effective for multi-step reasoning, arithmetic, and commonsense reasoning tasks.
Reliability: This aspect focuses on mechanisms to ensure the consistency and accuracy of the output. Examples include self-consistency checks, where the model performs several chain-of-thought rollouts and selects the most common conclusion, and iterative refinement, which involves a continuous feedback loop to correct and improve outputs.
c) The hierarchy of prompting: Foundational to advanced: A useful way to conceptualize prompting is as a hierarchy, where each level builds upon the previous one, moving from the least intrusive and simple methods to the most complex and robust. This approach mirrors principles from fields outside of AI, such as applied behavior analysis (ABA). The core idea of hierarchical prompting is to organize requests in a logical sequence, building “layers of context and detail” to achieve more accurate and useful responses. This approach, often referred to as ‘fading', involves progressively reducing the level of guidance as the model's performance improves, moving from most-to-least intrusive or vice versa. The following hierarchy provides a structured guide to this progression.
Level 1: Zero-shot prompting. This is the baseline technique, where the prompt provides only the task description without any examples. It relies on the LLM's extensive training data to understand and execute the task based on instructions alone. Zero-shot prompting is effective for simple, well-defined tasks like translation or content moderation, where a clear instruction is sufficient.
Level 2: Few-shot prompting. When zero-shot is insufficient, this technique involves providing one or more examples (input-output pairs) within the prompt to guide the model. The model learns the desired pattern, tone, or format from these examples, making few-shot prompts particularly useful for regulating output style and content. However, few-shot prompting is not a magic bullet; for complex reasoning tasks, it may not be sufficient to guide the model to a correct answer.
Level 3: Chain-of-thought (CoT) & advanced reasoning. This level introduces explicit guidance for the model's reasoning process. By adding a simple phrase like “Let's think step by step,” the model is induced to generate a sequence of intermediate steps, significantly improving its performance on complex multi-step problems. This is an emergent ability that arises with sufficiently large models and can be further enhanced by providing few-shot examples of a step-by-step thought process. Advanced reasoning techniques like Tree-of-thought (ToT) generalize this concept by generating multiple lines of reasoning in parallel, allowing the model to explore different paths to a solution.
Level 4: Automatic prompt optimization (APO). The most advanced level in the hierarchy, APO uses algorithms to automatically generate, evaluate, and refine prompts based on user-defined performance metrics. It is a data-driven approach that eliminates the need for manual, human-centric iteration, and represents a paradigm shift from manual prompt engineering to a scalable, automated discipline.
A common misconception is that effective prompting is about finding the perfect wording. A survey of over 1,500 academic papers reveals that this is a myth. The format and structure of prompts matter far more than the specific words used. A well-organized prompt using clear delimiters (such as JSON or XML tags) and a logical structure will consistently outperform an irregular prompt, regardless of its specific word choice. This indicates that effective prompting is less a matter of creative writing and more a matter of information architecture and systematic organization. Furthermore, a deeper understanding of the hierarchical prompting model reveals a striking parallel to behavioural psychology. The concept of a “least-to-most” or “most-to-least” prompting hierarchy is explicitly borrowed from applied behavior analysis (ABA), a field focused on teaching new skills and fostering independence. This suggests that LLMs, in some ways, behave like a learner. They require clear instructions, are susceptible to being over-prompted (which can lead to a form of prompt dependency), and improve with systematic, gradual guidance. This interdisciplinary parallel underscores that effective prompt engineering requires a fusion of knowledge from fields like psychology, information theory, and software engineering. The following table provides a unified, structured view of the hierarchical framework of Prompt Engineering field.
The landscape of automatic prompt optimization (APO) and a case study on Vertex AI: Manual prompt engineering is not a scalable solution for enterprise-grade applications. The inherent challenges of iterative refinement, lack of reproducibility, and performance degradation over time have given rise to a new, data-driven discipline: Automatic Prompt Optimization (APO).
a) The rise of automatic prompt optimization (APO): APO formalizes the process of prompt engineering as a mathematical optimization problem, where the objective is to maximize expected performance metrics over discrete, continuous, and hybrid prompt spaces. This approach fundamentally shifts the focus from human intuition to systematic, algorithmic search. Instead of relying on a single engineer's ability to tweak the phrasing, APO employs sophisticated methods to generate, evaluate, and refine prompts, thereby identifying the most effective input for a given task. The field is rapidly evolving, with methods borrowed from other areas of AI. A high-level overview of these core APO algorithms includes:
LLM-based optimization: This technique uses a generative AI model as an ‘optimizer’ to generate numerous prompt inputs for a given task. A separate ‘evaluator’ model then scores these inputs against a chosen metric, and the highest-scoring prompt is selected for use.
Evolutionary algorithms: This method applies principles of natural selection, such as selection, mutation, and crossover, to a number of guiding prompts. The “fittest” prompts (those that perform best on a given task) are selected to “reproduce,” creating new, mutated variants. This process is repeated over generations, allowing the system to explore a wide range of prompt variations and discover novel solutions.
Reinforcement learning (RL): RL-based approaches frame prompt optimization as a sequential decision process. An “agent” (the prompt) interacts with an “environment” (the LLM) to maximize a reward signal, such as a high accuracy score. The agent learns an optimal ‘policy’ for editing and refining the prompt based on the feedback it receives, enabling it to navigate the complex prompt space to find effective solutions.
b) Vertex AI's methodological advantage of its prompt optimizer: The perception that Vertex AI's prompts are more accurate is a direct result of its strategic focus on providing an end-to-end platform with a robust APO framework. The core of this advantage is the Vertex AI Prompt Optimizer, a service that employs a closed-loop, automated system for prompt refinement. The underlying mechanism is a two-model system that functions as an iterative LLM-based optimization algorithm. LLM users begins by providing a “seed prompt” (an initial, manually crafted prompt template) and a set of “labelled samples” in a structured format (input-ground truth pairs). The process then unfolds in a fully automated fashion: an optimizer model generates new prompt candidates, which are subsequently evaluated by a separate evaluator model against the user-defined metrics. The system then automatically selects the best instructions and few-shot examples to enhance the prompt. This is a direct implementation of the LLM-based optimization algorithm discussed earlier. This process is fundamentally different from one-time prompt generation. It is not about a single, static prompt but about an automated, continuous process of evaluation and refinement. Most of the AI generated prompts are not even better is a side effect of non-optimized generation. The reason Vertex AI's prompts are better is not that the initial generation is inherently magical, but that the platform facilitates an automated, continuous, data-driven optimization process that is crucial for production-grade applications. A core finding from my research is that a prompt's performance is not static; it degrades over time as models change, data distributions shift, and user behavior evolves. A systematic, continuous optimization process can lead to a significant performance improvement over time compared to a static prompt. This leads to the understanding that the best tools are not those that provide the best single prompt, but those that provide the best system for evolving prompts. Vertex AI's advantage lies in its recognition of this fact and its provision of the tools to address it.
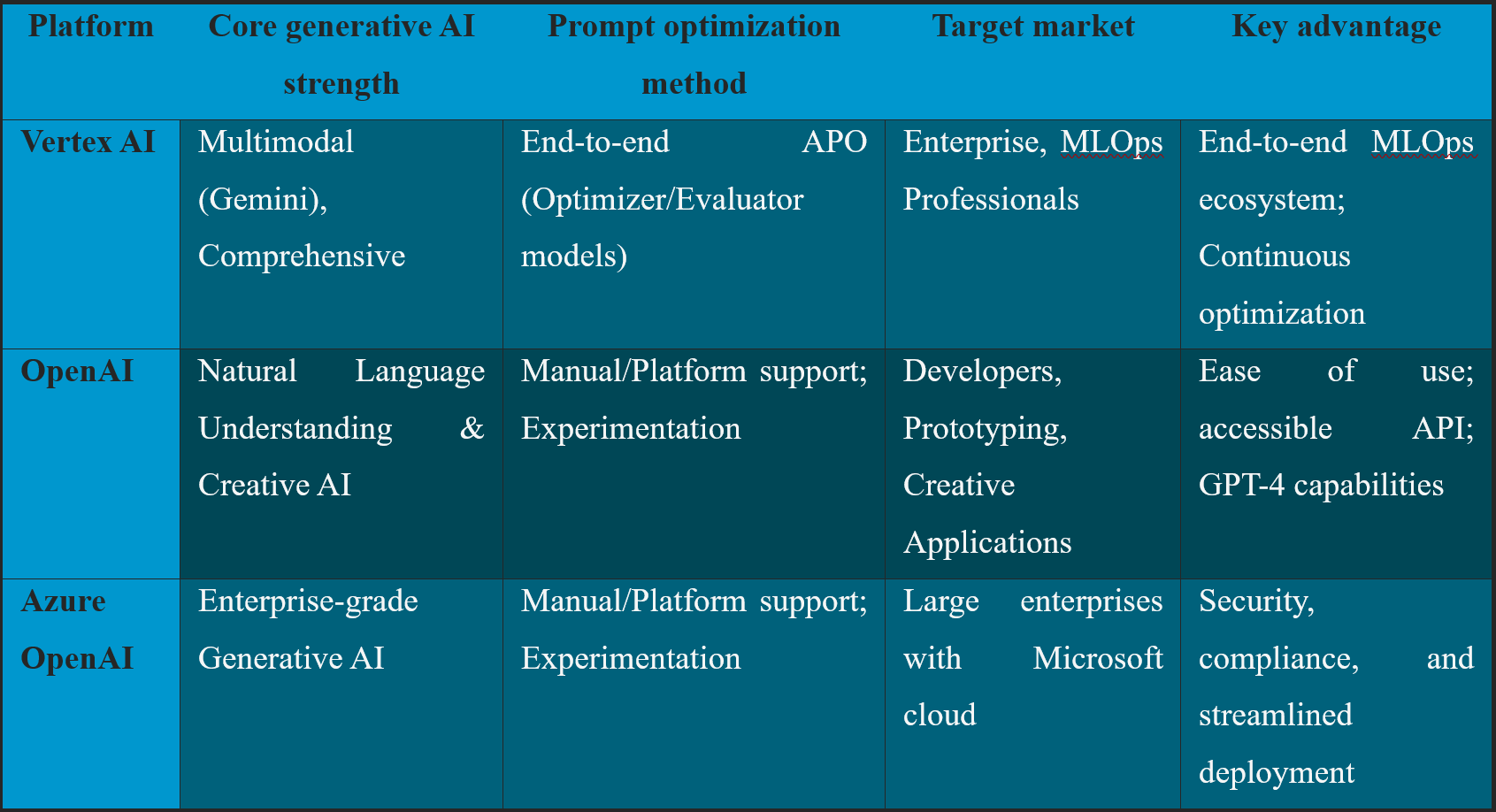
c) Comparative analysis: Vertex AI vs. Rivals: A comparison of Vertex AI with leading competitors reveals that the choice between platforms is not a simple matter of ‘better’ or ‘worse’ but rather a strategic decision based on purpose and target market.
Vertex AI vs. OpenAI: While OpenAI is the superior choice for advanced natural language processing and generative AI tasks and creative content creation, largely due to its cutting-edge GPT models, Vertex AI is a fully-managed, unified AI development platform designed for leveraging machine learning model development and deployment at scale. OpenAI’s API is known for its ease of use, making it ideal for developers and rapid prototyping. Conversely, Vertex AI provides an extensive, integrated MLOps ecosystem that, while having a steeper learning curve, is better suited for complex, enterprise-grade projects that require a comprehensive suite of tools for training, tuning, and deploying models.
Vertex AI vs. Azure OpenAI service: Testing & experiments suggest a nuanced trade-off between these two platforms. Azure OpenAI Service has a slight edge in ease of deployment and specific features like ‘AI Text Summarization’ and ‘AI Data Encryption,’ making it an appealing option for companies with stringent data protection requirements and a pre-existing Microsoft ecosystem integration. Vertex AI, by contrast, is praised for its AI high availability and flexibility in training data management, highlighting its strength in providing robust, production-ready systems for managing a diverse set of models and data.
The perception of Vertex AI's superior accuracy is a direct result of its platform-centric approach. It is not just a prompt generator; it is an end-to-end system for systematically developing, testing, and deploying robust AI applications. Its APO framework is a key part of this, ensuring that prompts are not static but continuously optimized based on real-world data and user-defined metrics. The following table provides a clear, side-by-side comparison.
Principles for effective prompt development and continuous optimization: The analysis presented suggests a new set of guiding principles for successful prompt development, moving from a reliance on heuristics to the adoption of a structured, engineering-based methodology.
a) The Prompt as a product mentality: Successful prompt development should be treated like any other product feature. This means it requires ongoing maintenance, improvement, and optimization based on real user data. A prompt is not a one-time configuration; it is a dynamic component that must be monitored and refined continuously to ensure it continues to meet user needs as models and data evolve.
b) Best practices for design: While specific techniques vary, a few best practices are universal for effective prompt design:
Start with structure, not wording: The effort to find the perfect wording is largely misplaced. A well-structured prompt that uses clear delimiters, such as JSON or XML tags, and a logical flow will yield more consistent improvements than hours of wordsmithing.
Be specific, provide context: Avoid ambiguous or vague instructions. A prompt should be a clear roadmap for the chosen model, complete with all necessary context and background information to prevent unhelpful outputs.
Iterate and refine: Prompting is rarely a one-and-done task. A simple feedback loop of testing, evaluating, and refining the prompt based on the model's response is essential for achieving desired results.
c) The role of systematic evaluation: The most significant shift in mindset required for effective prompt engineering is the prioritization of testing. Extensive research from China & USA strongly suggests that the work of prompt development is ‘really test development’. If the prompt is an unstable variable, a robust evaluation system is the constant that defines success. The best source for these tests is a gold mine sitting right in front of you: your production data. By systematically finding and fixing problem cases from real-world usage, organizations can continuously improve their prompts and ensure they meet user expectations. This process is greatly aided by tools and platforms that allow for the versioning of prompts and datasets, enabling a rigorous, reproducible, and engineering-based approach.
d) The future of prompting from heuristics to engineering: The ultimate solution to the systemic failures of automated prompting is not a secret phrase or a new, magical model, but the adoption of sophisticated, automated methodologies. The future is a fusion of human-led strategy (defining objectives and evaluating results) with machine-led optimization. The ongoing research in evolutionary algorithms, reinforcement learning, and LLM-based optimizers is rapidly transforming a once-intuitive art into a rigorous and scalable engineering discipline. This evolution is the critical path to building reliable, enterprise-grade AI applications.
Conclusion: The high failure rate of automated prompts stems from a fundamental misunderstanding of LLMs as deterministic systems. The solution lies in a paradigm shift: from treating prompt engineering as a series of creative tricks to a structured, data-driven, and continuously-optimized engineering discipline. The problems of non-determinism, hallucination, and bias are not unbeatable flaws but challenges that can be mitigated by applying mature software development and machine learning principles, such as systematic testing, continuous evaluation, and version control. I repeat, the perception of Vertex AI's superior accuracy is a direct result of its strategic focus on providing an end-to-end platform with a robust APO framework. Unlike tools that offer a one-time prompt generation, Vertex AI provides a systematic solution to the problems of scale, non-determinism, and performance degradation. By automating the iterative refinement and evaluation process, it empowers users to define success through data and metrics, while the system autonomously optimizes the prompts to achieve those goals. Vertex AI’s advantage is its ability to operationalize the continuous improvement cycle that is essential for reliable AI deployment. The future of reliable, enterprise-grade AI applications is inseparable from the future of automated prompt optimization. The ultimate goal is not to eliminate the human, but to elevate them, allowing domain experts and engineers to focus on defining clear business objectives and evaluating the impact of the AI system, while the tools autonomously optimize the prompts to achieve those goals. Future involves embracing a holistic, engineering-first approach that views the prompt not as a standalone artifact, but as a dynamic component within a robust, scalable, and continuously-optimized AI system.
Join Jaideep on Peerlist!
Join amazing folks like Jaideep and thousands of other builders on Peerlist.
1
3
0