Lessons from Vibe-Coding My First Project to App Store
Available here: https://vitalityapp.fit/
TL;DR
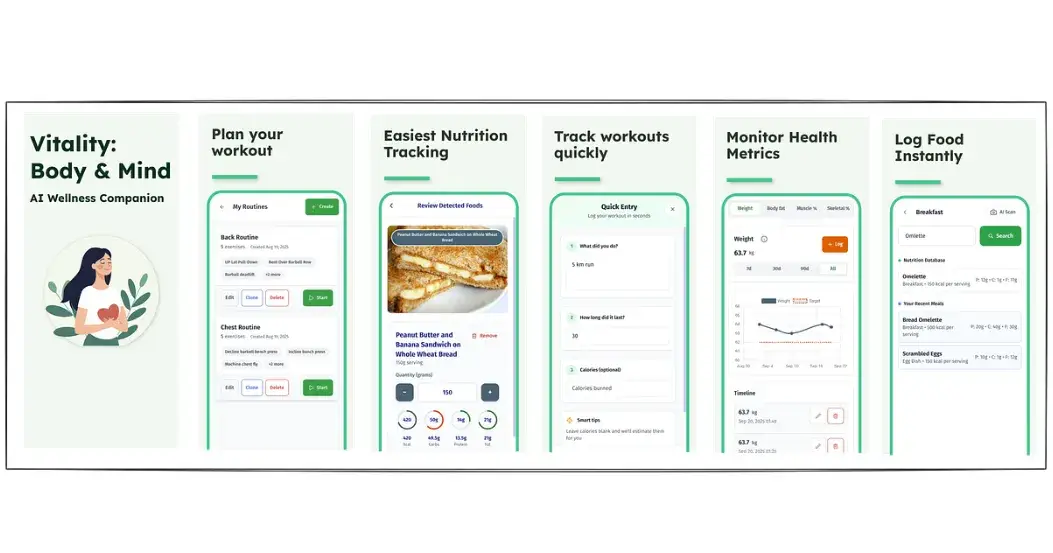
I recently shipped Vitality — an AI-assisted wellness app.
I used LLMs heavily (Cursor / Claude / GPT-Codex), Supabase for auth, PostgreSQL for data, Capacitor for iOS/Android, Cloudflare Pages for fast previews, and Codemagic for mobile CI — and also tools like Stitch by Google and ChatGPT for product research.
This is the first app I’ve ever launched. This post details the actual process I went through: from idea → working product → App Store submission → final implementation and release.
Tools like builder.io and Cursor helped me move fast initially — but only because I paired them with tight scoping and disciplined review.
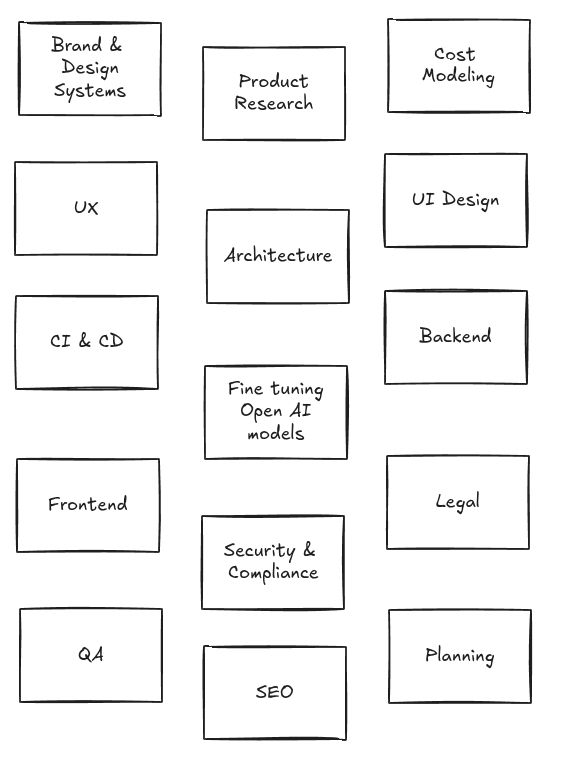
The actual process involved much more than just coding — planning, research, testing, design, cost modeling, branding, SEO, CI/CD and architecture were all part of it.
The Idea that I Couldn’t Shake
Like many indie hackers, I had a nagging idea I just had to build. For years I used calorie and workout trackers. Over time, three pains became obvious:
Price vs. value. Many premium fitness apps have expensive plans compared to the actual infrastructure costs.
Over-tracking fatigue. These apps excel at tracking and counting — but they fall short of analyzing how meals, workouts and energy levels impact lifestyle over time.
From Idea to Plan
Here’s how I translated the idea into an execution plan:
I brainstormed and captured key points on a whiteboard.
I used o3 to organize thoughts, tighten scope for v1, and produce a lean PRD.
I ran a market scan using deep research and the web-AI agent abilities of ChatGPT — validating market size, sentiment and competitor features quickly.
I sketched screens on paper (visualizing app functionality), then translated those sketches into wireframes.
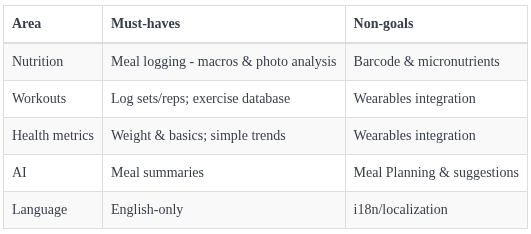
I defined strict constraints — must-haves for the first draft. Keeping non-goals in the backlog helped keep the scope tight for the initial launch.
AI-assisted development workflow
Scaffolding the initial repository was easier with tools like lovable.dev and builder.io — they helped build major UI components quickly.
Once scaffolding was ready, I integrated third-party services (Supabase, data modeling, RevenueCat/Stripe, Sentry) offline.
Smaller commits + git bisect helped catch few of the regressions faster.
LLM outputs are not always correct — so I had multiple rounds of reviews of schema changes, index changes, access policies updates, bucket rules changes, etc.
I used ChatGPT to quickly scaffold scripts that filtered and refined the OpenFoodFacts public dataset — creating a moderate-sized training set for fine-tuning my model.

What helped me
PR previews from Cloudflare helped me ship features quickly — each PR had its own shareable ephemeral URL to validate changes.
Initial design-to-code conversion was relatively easy with builder.io, though fine-tuning UI details later took more effort.
I didn’t expect tiny embedding models to work so well in the browser (using WebGPU). They were fast enough to enable great search UX even on slow devices (see [gte-small on Hugging Face]).
I spent extra time reviewing — because LLM-generated code sometimes had flaws: overly complex database schema, inefficient indexes, wrong RLS (row-level security) rules, latency issues, etc.
If you start with pen and paper and visualize the idea via wireframes, you can build a working UI/UX with tools like builder.io. Then work offline, review carefully, clean code smells, and iterate on backend, UI/UX, or native integrations.
Join Kapil on Peerlist!
Join amazing folks like Kapil and thousands of other builders on Peerlist.
0
2
0