A Rookie’s understanding of AI
From Zero to "I Get it! "

Hey there!
This quick guide is for absolute beginners students, creative folks, or anyone curious about AI but not sure where to start. In just 15 minutes, you'll get how AI handles text, what tokenization, embeddings, and GPT mean and most importantly, how they all connect in everyday tools like chat assistants and search engines.
AI in One Minute: The Big Picture
AI = software that learns patterns from data.
It’s built on three pillars:
Data (examples it learns from)
Model (the pattern learner)
Task (what you want it to do)
Ever noticed how YouTube suggests videos you might like or how your phone autocorrects your typos? That’s AI learning patterns—simple and powerful.
Language is Hard for Computers: Why We Need Tricks
To a computer, plain text is just messy characters—like “hello” is incomprehensible unless broken down. As we all know all the tasks that we do are finally being converted into 0 and 1's. That’s why we use two clever tricks:
Tokenization: Cutting text into manageable bits.
Embeddings: Turning those bits into meaningful numbers
Tokenization : Breaking things Down
When you see the word "tokenization," you might guess it means breaking something into pieces. But why do we need to do this?
Think about how you’re reading this blog right now. You don’t read the whole page at once—you read it word by word, sometimes even pausing at punctuation. In a way, you’re breaking the text into smaller, understandable parts as you go.
Machines and large language models (LLMs) work in a similar way. They can’t understand a sentence or a paragraph all at once. Instead, they need the text to be split into smaller pieces. These pieces are called tokens. The process of splitting text into tokens is called tokenization.
So, just like you break down a sentence to understand it, machines break down text into tokens to make sense of it. But watch out. Different models tokenize the same sentence differently, and models have token limits (go over, and your input might get cut off)
now what we are using is a word tokenization scheme but there are many more
Some common tokenization types :
Character tokenization :
Splits text into individual characters.
Example: “hello!” → [“h”, “e”, “l”, “l”, “o”, “!”]
Word tokenization
Splits on spaces/punctuation.
Example: “unbelievable!” → [“unbelievable”, “!”]
Subword tokenization (what most LLMs use: BPE, WordPiece, SentencePiece)
Splits words into frequent pieces that can recombine.
Example: “unbelievable!” → [“un”, “believ”, “able”, “!”] (conceptually)
Byte/byte-pair tokenization (GPT-style)
Works at the byte level, then merges frequent byte pairs.
Handles any script, emoji, code, even unknown symbols.
Try it
https://tokenizer-zeta.vercel.app/ : check out a custom tokenizer I made with a custom scheme
https://tiktokenizer.vercel.app/ : Visualize tokens and counts for various llm models out there.
Vector Embeddings : A Map of Meanings
After tokenization, models still need a way to represent meaning. Since machines don’t “see” words, they use numbers. That’s where vector embeddings come in.
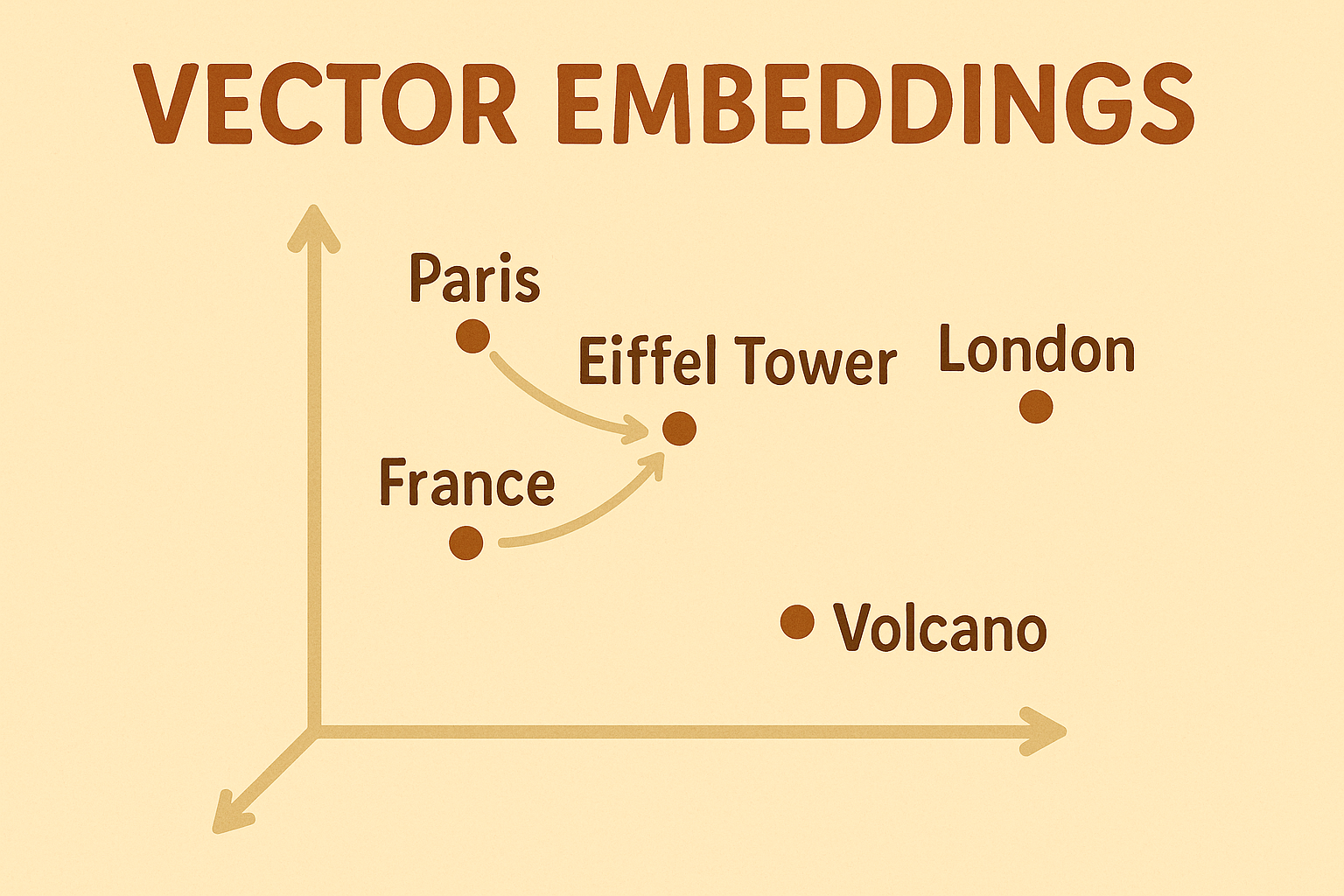
Think of how your brain connects ideas. When you hear “Paris,” you might also think “Eiffel Tower.” When you hear “Superhero,” related ideas pop up. Your mind has a mental map of meanings.
Embeddings give computers a similar map. Each word, phrase, or document is turned into a vector - a list of numbers. Vectors that mean similar things end up close together in this multi‑dimensional space, different things are farther apart.
Why this helps
Semantic search: “capital of France” finds texts about “Paris,” even without exact matches.
Clustering and deduplication: group similar sentences or documents.
Recommendations: “You might also like…” based on meaning, not just keywords.
RAG: quickly fetch the most relevant passages to feed the model.
A quick mental picture
Imagine a city map of ideas. “Cat” sits near “kitten” and “pet,” but far from “volcano.”
Relationships also form patterns. Country : capital is a similar pattern across many pairs.
Try it
https://projector.tensorflow.org/ : Visualize and compare embeddings
https://platform.openai.com/docs/guides/embeddings/embedding-models : check out the OpenAI embedding models and its details
GPT : Generative Pre-trained Transformer
At its core, GPT is a next‑token predictor: given some text, it predicts the most likely next token, then the next, and so on to generate a response.
Breakdown of the name
Generative: it can produce new text.
Pretrained: it learned from large amounts of data before you use it.
Transformer: the neural network architecture it uses, powered by attention.
OpenAI introduced a chat interface (ChatGPT) that made GPT easy to use in conversation, sparking mainstream adoption.
Imagine a super smart parrot that read every book in the world and got great at predicting the next word. GPT doesn’t really “understand” like we do—it just gets good at guessing what comes next based on patterns.
That’s why it seems smart…but it can still be confidently wrong, so always double-check!
How It Works Together: From Text to Answers
Step-by-step flow:
You type a sentence.
A tokenizer slices it.
Slices become vectors (embeddings).
The model predicts the next tokens.
Tokens are turned back into text.

Retrieval-Augmented Generation (RAG): Giving GPT a Notebook
Here’s the thing—GPT, no matter how impressive, has a memory cutoff. If it was trained in 2023, it won’t know who won the 2025 Cricket World Cup.
That’s where Retrieval-Augmented Generation (RAG) comes in.
Think of RAG as letting GPT bring a notebook to an exam.
When it gets a question, it quickly flips through its notes (your database, a PDF, or even the web), finds the relevant bits, and then uses them to answer you.
How embeddings fit in here: embeddings help GPT find the “right page” in the notebook before writing its answer.
Where RAG shines:
Chat over your personal notes, documents, or research papers.
Customer support bots that always have the latest product info.
AI tools for analysts that pull from live data.
Tokens, Costs, and Practical Tips
Here’s the part that surprises beginners: more words = more cost in most AI APIs.
Why? Because every token you send or receive costs computing power.
More tokens also risk hitting the context limit—the maximum “memory” the model has per conversation.
Pro tip:
Use the Role + Task + Context + Examples + Constraints structure for prompts.
Example:
“You are an English teacher (Role). Correct this essay (Task). Here’s the essay: … (Context). Make 3 suggestions (Constraints).”
Myths, Busted
“AI understands like humans” → No, it’s pattern matching.
“More tokens = better answers” → Clarity matters more.
“Embeddings are just for search” → They’re also for grouping, recommendations, and memory.
“GPT knows everything” → It needs fresh info for current events.
Conclusion
If you’ve made it here, you now have the mental map:
Text → Tokens → Embeddings → GPT → Answer
You know why tokenization matters, how embeddings give meaning, and how GPT strings it all together.
So—
Next time someone says, “AI is magic,” you can smile and say,
“Not magic. Just math, maps, and some really clever parrots.”
Join Prasad on Peerlist!
Join amazing folks like Prasad and thousands of other builders on Peerlist.
0
8
0