The Brain Was Never the Whole Story: Understanding Agent Harnesses
A few months ago, I watched an AI coding agent trace through an entire repository, identify the root cause of a bug, modify several files, run tests, and propose a fix. It felt less like a chatbot and more like a teammate.
Like most people, my first instinct was to wonder and ask:
“Which model is this using?”
Naturally, I assumed the secret was the model. Maybe it was using the latest reasoning model. Maybe it had a larger context window. Maybe it had some hidden capability the rest of us didn’t have access to yet.
But the more I dug into how modern agents actually work, the more I realized I was focusing on the wrong thing.
The model wasn’t the entire story. It was everything surrounding it.
The memory system.
The tools.
The permissions.
The workflow.
The orchestration.
The invisible machinery that allows a model to stop behaving like a chatbot and start behaving like an agent.
That machinery has a name: The harness.
And if you’ve been building, using, or experimenting with AI agents lately, understanding harnesses may be more valuable than understanding the latest model release.
The Difference Between a Model and an Agent
It’s easy to forget how limited a raw language model actually is. At its core, a large language model is a prediction engine.
A raw model is incredibly good at generating text. Give it context, ask a question, and it will usually produce a thoughtful answer. But that’s where its responsibility ends. It doesn’t wake up tomorrow remembering what happened today. It doesn’t check whether its answer worked. It doesn’t pause and think, “Maybe I should investigate further before responding.”
The interaction begins and ends inside a single response.
That’s why a model and an agent aren’t the same thing.
An agent behaves differently. It isn’t defined by how well it answers a question. It’s defined by what happens after the first answer.
Instead of stopping, it keeps working. It can open files, search documentation, run commands, inspect results, revise its approach, and continue moving toward a goal. It can learn from what it discovers along the way and decide what to do next.
The interesting part is that this difference doesn’t come from the model itself.
It comes from the system wrapped around the model: The harness.
One analogy I often think of is like a car. The model is the engine, and the engine is unquestionably important. Powerful, sophisticated, and essential. Without it, nothing moves. But an engine alone can’t take you anywhere. To become something useful, it needs steering, brakes, transmission, sensors, navigation, controls, and dozens of supporting systems working together.
The engine provides power.
The vehicle provides direction.
AI agents work in the same way. The model supplies intelligence, but the harness gives that intelligence memory, tools, structure, and the ability to act in the world.
Which is why one of the most useful mental shifts when thinking about agents is this:
It’s not:
Model = Agent
It’s:
Model + Harness = Agent
Press enter or click to view image in full size
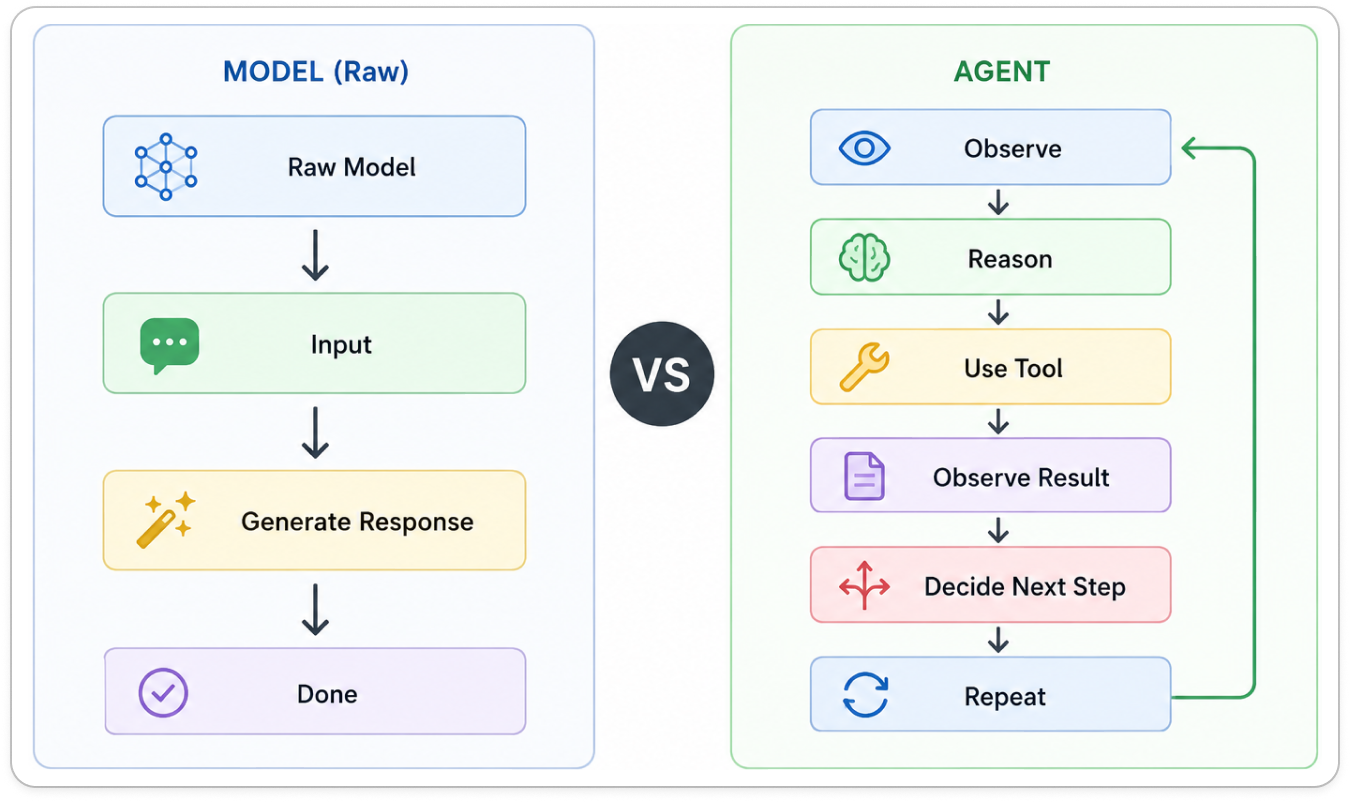
Agents aren’t defined by a single answer. They’re defined by continuous interaction with their environment.
This distinction might sound academic.
It isn’t.
In March 2026, researchers at Tsinghua University and Stanford independently showed that the same model could produce dramatically different outcomes depending on the harness surrounding it.
In some cases, the difference wasn’t marginal.
It was multiples.
The model stayed the same.
The architecture changed.
You Already Use Harnesses Every Day
The funny thing is that most of us have been using harnesses for months without realizing it.
When you open a coding tool and ask it to explore a repository, suggest changes, run tests, and explain its reasoning, you’re not interacting with a language model directly. You’re interacting with a carefully designed system built around that model. Products like Cursor, Anthropic Claude Code, OpenAI Codex, and Windsurf all rely on harnesses.
The model might be the same, but the experience isn’t.
The model is only one piece of the puzzle.
What makes these tools useful is how they manage information, tools, permissions, memory, and decision-making.
That’s also why the same model often behaves differently depending on where you use it.
A model running within a single product can feel remarkably capable. The same model running inside another can feel unreliable, forgetful, or inefficient.
The difference isn’t intelligence.
The difference is architecture.
Frameworks Build Agents. Harnesses Run Them.
This is where many discussions become confusing.
People often use the words framework and harness interchangeably, even though they solve different problems.
Frameworks such as LangChain, LangGraph, AutoGen, or CrewAI give developers building blocks. They provide useful abstractions for things like memory, workflows, retrieval, state management, and communication between agents. But they don’t tell you how everything should fit together. That’s still your responsibility.
Think of them as a box of components. You still decide how those components fit together. You are the architect. A harness approaches the problem from the opposite direction; it gives you a functioning system. The pieces are already assembled. The memory layer is already connected. The tools are already available. Permissions are already enforced. The workflow is already defined. Rather than deciding how the architecture should work, you provide the objective, and the system takes it from there.
Frameworks help humans build agents.
Harnesses help agents do work.
It’s a subtle distinction, but an increasingly important one.
The Operating System Nobody Sees
One of the most useful mental models for understanding harnesses comes from traditional computing.
Press enter or click to view image in full size
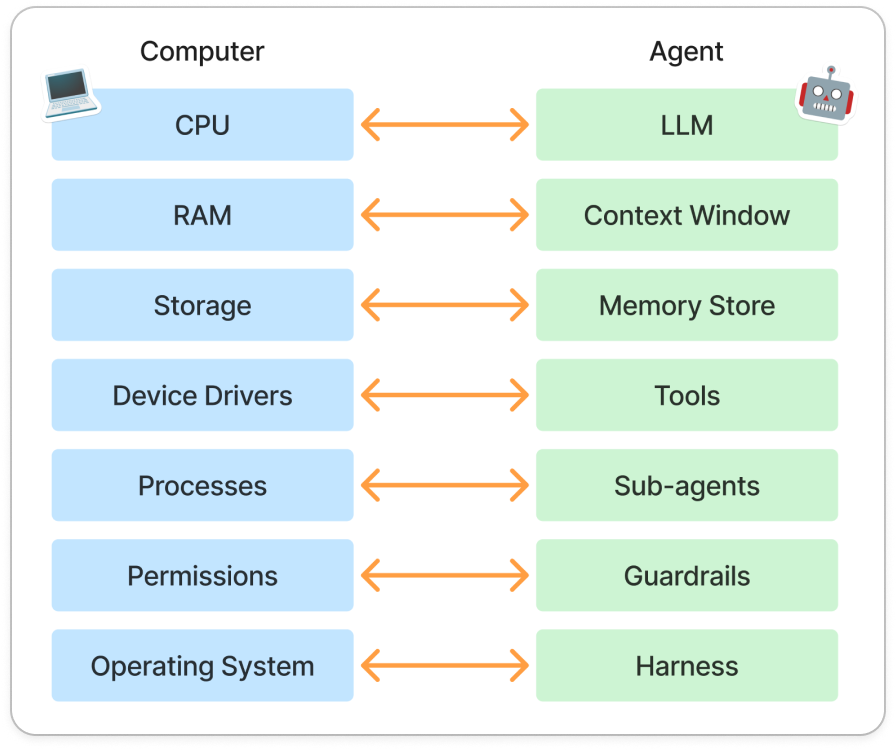
Thinking of the harness as an operating system makes many agent behaviors easier to understand.
Think about your laptop for a second. The processor inside it is incredibly powerful, but on its own, it doesn’t know where your files live, which application should open a document, how much memory a program can use, or whether an app should even have permission to access your camera. That’s the job of the operating system. It quietly coordinates everything happening behind the scenes so the hardware can actually do useful work.
Imagine the language model as a CPU. The CPU is powerful, but it doesn’t manage files, memory, storage, or devices on its own. That’s the job of the operating system. The operating system decides what the processor sees, what information stays in memory, which programs are allowed to run, and how resources are allocated.
Modern agents work in a surprisingly similar way.
The model acts like the processor. The context window behaves like RAM: fast, but limited. External memory systems act as storage, preserving information beyond a single session. Tools behave like device drivers that allow interaction with the outside world, allowing it to search, read, write, execute, and interact. And sitting above all of it is the harness, which acts as the operating system, coordinating what the model sees, remembers, and does next.
Once you start thinking this way, the most interesting question changes.
Instead of asking:
“Which model should I use?”
You start asking:
“What kind of operating system am I building around it?”
Every Agent Lives Inside a Loop
Every modern harness looks different on the surface. Some are optimized for coding. Others for research, automation, or customer support.
But beneath those differences, most of them rely on the same underlying building blocks. The names vary. The implementations vary. The ideas don’t. Once you understand these components, you’ll start seeing them inside nearly every agent system you use.
If the harness is the operating system, the loop is its heartbeat that keeps everything moving.
Every agent begins with a simple cycle.
Press enter or click to view image in full size
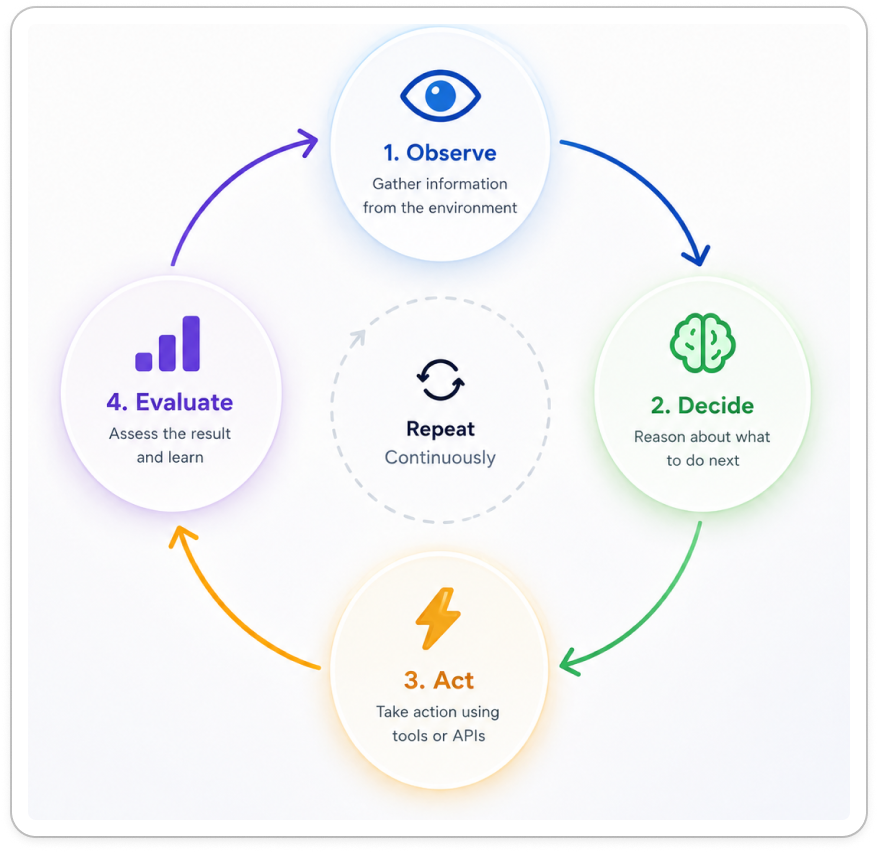
The observe-decide-act loop is the heartbeat of every modern agent.
It looks at the current situation, decides what to do next, takes an action, observes what changed, and then decides again.
When an agent opens a file, that’s one cycle.
When it analyzes the contents and decides to inspect another file, that’s another cycle.
When it executes a command and evaluates the output, that’s another cycle again.
Each action creates new information, and that information shapes the next decision. The agent isn’t moving in a straight line; it’s constantly adjusting its understanding of the problem as it works.
This cycle continues until the task is complete — or until the harness decides it’s time to stop.
This sounds obvious, but this loop is what separates an agent from a chatbot.
A chatbot gives you an answer.
An agent keeps working.
The harness is what keeps that cycle alive. Harness is the layer that keeps bringing the model back into the problem, allowing it to learn from each step instead of ending the conversation after the first response.
Without it, the conversation ends after the first answer.
Memory: Knowing What to Forget and What to Keep
One of the biggest misconceptions about AI is that more memory is always better.
Humans know that’s not true.
Imagine trying to solve a design problem while simultaneously remembering every Slack message you’ve ever received. At some point, information becomes noise.
Agents face the same challenge. Every file they read, every tool they use, every result they observe, and every decision they make adds another layer to their context. Eventually, the context window fills up.
This is where the harness quietly steps in and makes decisions. It decides what information still matters, what can be compressed into a summary, and what should disappear entirely.
The best agents aren’t the ones that remember everything. They’re the ones that know what to forget.
But memory isn’t only about deciding what stays inside the context window. It’s also about preserving progress across time.
Without persistence, every interruption becomes a reset. Every crash erases history. Every restart forces the agent to begin again.
Modern harnesses solve this by recording observations, decisions, tool results, and state transitions as work progresses. If execution stops unexpectedly, the system can reconstruct the session and continue from where it left off.
Good memory systems, therefore, serve two purposes at once: they remove information that no longer matters while preserving information that must survive.
Giving Intelligence Hands and Eyes
A model can reason all day long, but reasoning by itself rarely changes anything.
Imagine asking someone to solve a problem while blindfolded, unable to touch anything, read anything, or interact with the world around them. No matter how intelligent they are, their ability to help would be limited.
Agents face a similar challenge.
An agent needs ways to interact with its environment. It needs to inspect files, search through repositories, execute commands, call APIs, browse documentation, and update information when necessary. These capabilities are what we call tools.
But I like thinking of them differently.
Tools are the agent’s senses and limbs.
A search tool gives the agent visibility. A terminal command gives it the ability to act. A file editor allows it to change its environment.
Without tools, an agent remains trapped inside its own thoughts.
With tools, it can test those thoughts against reality.
Tools change that relationship. They allow the agent to move from imagination to observation, from assumptions to evidence.
Tools provide capabilities. Skills provide repeatable ways of using those capabilities. Over time, teams develop preferred workflows for debugging, researching, reviewing code, or handling incidents. Modern harnesses often encode these workflows as reusable skills so agents can apply proven approaches instead of rediscovering them from scratch every time.
Some of these skills come preinstalled. Reading files, searching code, navigating directories, editing content, and executing commands are often treated as foundational abilities. They aren’t specialized expertise. They’re the equivalent of knowing how to read, write, and use a keyboard.
The most capable agents aren’t built entirely from sophisticated reasoning. They’re built on top of reliable fundamentals that work consistently every time.
When One Agent Becomes Many
There’s a moment in every project when a single thread of work stops being enough.
Designers experience this when research, wireframing, prototyping, and stakeholder communication all start happening at once. Engineers experience it when debugging, testing, reviewing, and documenting begin competing for attention.
The same thing happens to AI agents.
Imagine asking an agent to investigate a failing production service. To solve the problem, it may be necessary to inspect logs, analyze infrastructure configurations, search through documentation, verify assumptions, and propose fixes. Trying to do all of that inside a single conversation thread quickly becomes messy.
Modern harnesses solve this problem the same way humans do: by delegating.
Instead of forcing one agent to handle everything, the harness can create specialized sub-agents. One agent investigates the logs. Another explores possible root causes. A third validates whether the proposed solution actually works.
Each operates in its own isolated workspace with its own instructions, context, and tool access. Once the work is complete, their findings are collected and brought back together.
What’s interesting is that this isn’t really about making agents smarter. It’s about reducing cognitive clutter.
A focused worker almost always performs better than one trying to juggle ten responsibilities at once.
The harness becomes less like a chat interface and more like a project manager, deciding when work should be split apart and when it should come back together.
The Prompt You Never See
Most people assume an agent gets its behavior from a single system prompt sitting quietly at the beginning of the conversation.
That’s technically correct.
But it also hides a more interesting reality.
In modern agent systems, the system prompt is rarely a single block of text written by a developer and forgotten.
It’s assembled.
Imagine joining a new company.
Nobody hands you a single document containing every rule, process, expectation, and piece of institutional knowledge. Instead, information comes from everywhere. Team playbooks. Design principles. Internal documentation. Security policies. Project briefs. Conversations with colleagues. Notes from previous meetings.
Agents work similarly.
Before the model ever sees your request, the harness is often busy gathering context from multiple places. It may pull instructions from repository files, project-specific guidelines, organizational policies, previous session summaries, memory stores, or team conventions. Each source contributes a small piece of the puzzle.
The model never sees these sources individually. The final prompt becomes a carefully assembled package of context. In some ways, the harness acts like a librarian preparing research material before handing it to the model. The model only sees the final stack of information.
The harness decides what belongs in it.
Dynamic prompts create a tradeoff. More context can improve performance, but constantly rebuilding prompts reduces caching efficiency. Modern harnesses, therefore, balance personalization with stability, deciding when new information is worth introducing and when consistency matters more.
This turns prompt engineering from writing a clever paragraph into managing an evolving knowledge system.
Invisible Checkpoints
Every mature system eventually needs customization. Some organizations require approvals before sensitive actions. Others need logging, compliance checks, notifications, or monitoring.
Rather than modifying the harness itself, modern systems expose hooks: interception points that run before or after actions. A hook can inspect a request, block it, modify it, or record the outcome.
This allows organizations to extend behavior without rewriting the underlying architecture. If the harness is the operating system, hooks are its plugin system.
Most users never notice them. Enterprise teams rely on them heavily.
The Layer Between Useful and Dangerous
The more capable agents become, the more important one question becomes:
What should they be allowed to do?
It’s an uncomfortable question because the capabilities that make agents useful are often the same capabilities that make them risky.
Reading a file is useful.
Deleting a file uses a very similar mechanism.
Running a diagnostic command is helpful.
Running a destructive command is not.
This is why every serious harness contains a permissions layer. Before a tool runs, the harness evaluates whether the action should be allowed. Some actions require only read access. Others require workspace access. The most sensitive operations may require explicit approval from a human.
The key distinction is that permissions act before execution, not after. The harness prevents risky actions rather than trying to recover from them later.
The interesting part is that permissions are often dynamic:
Listing files in a directory might be considered harmless.
Deleting an entire directory is not.
The harness evaluates intent, context, and risk before deciding how much freedom the agent should receive. Most demos focus on what agents can do. The real engineering challenge lies in defining what they shouldn’t do.
Autonomy without boundaries isn’t impressive.
It’s reckless.
The harness provides those boundaries.
Press enter or click to view image in full size
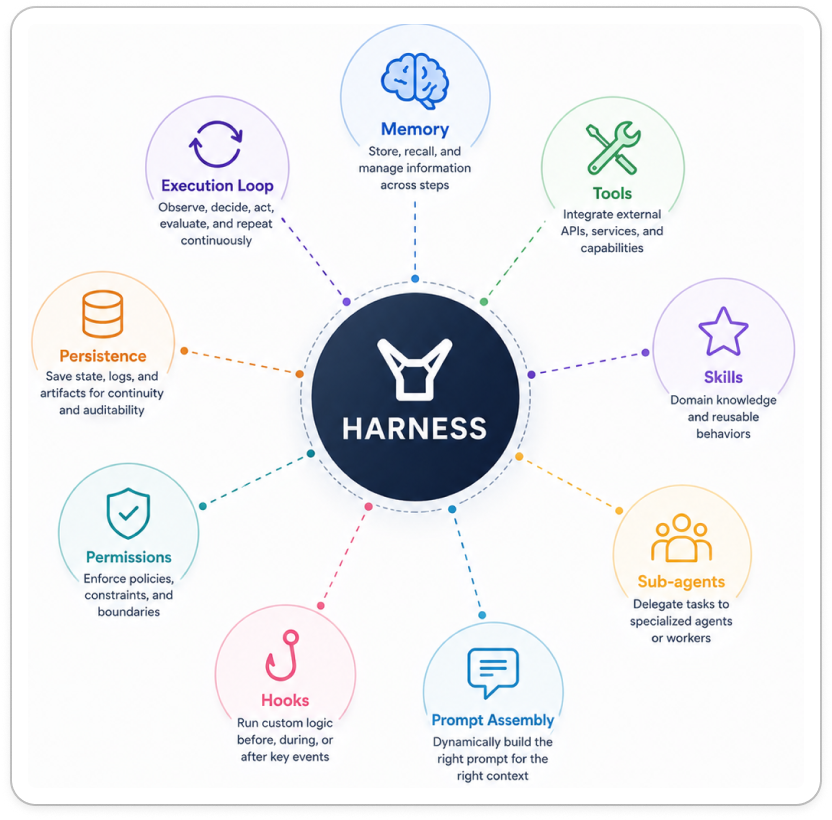
Most modern agent systems combine the same core building blocks, even if implementations differ.
The Research That Changed the Conversation
For a long time, all of this felt like an implementation detail. Important implementation detail, certainly. But still secondary to the model itself. Then, a pair of research papers published in March 2026 challenged that assumption.
The first came from researchers at Tsinghua University led by Pan and colleagues.
Their question was surprisingly simple:
What if an agent’s control logic wasn’t written in code at all?
Instead of expressing orchestration rules through Python scripts, configuration files, or complex workflows, they experimented with describing the harness itself in structured natural language.
Their architecture separated the system into three layers.
Press enter or click to view image in full size
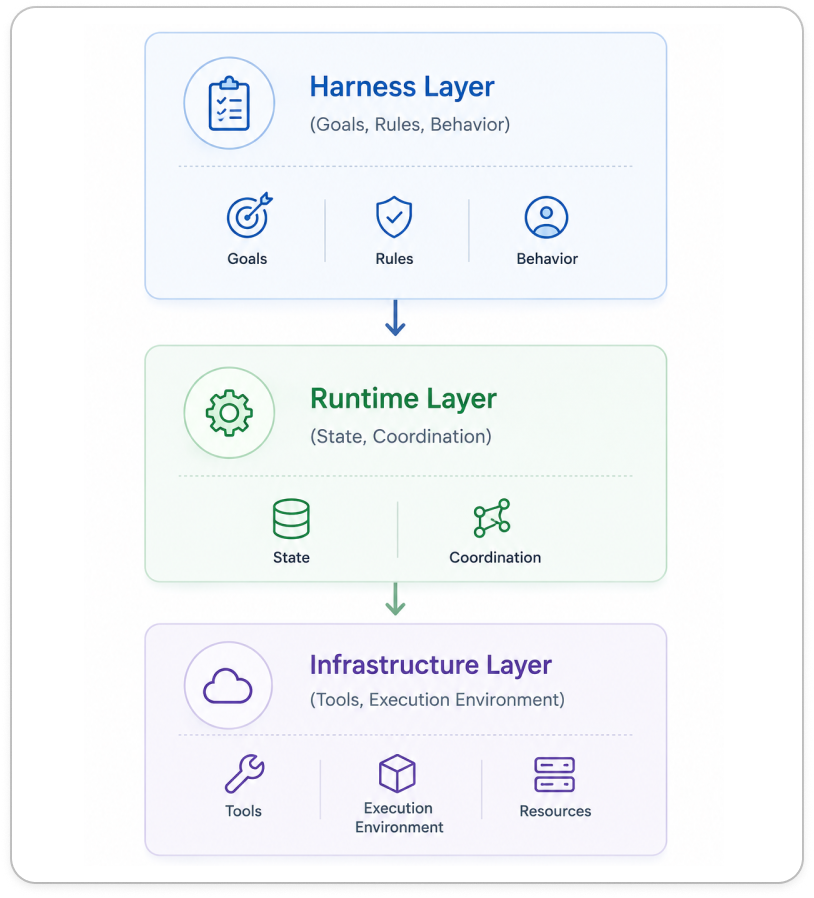
Tsinghua researchers separated behavior from infrastructure, allowing harness design to be evaluated independently from model design.
At first glance, this sounds like an implementation detail.
It wasn’t.
By separating runtime mechanics from behavioral logic, researchers could modify the harness while keeping everything else constant. For the first time, they could evaluate harness design independently from model design.
The result wasn’t just a new architecture.
It was the beginning of a new discipline: Harness engineering.
The results suggested that the way an agent is structured can significantly influence performance, efficiency, and behavior even when the underlying model remains unchanged.
The second paper pushed this idea even further. Researchers at Stanford University, led by Omar Khattab, explored a fascinating possibility:
If harness design matters this much, can we optimize the harness itself?
Their system analyzed failed execution traces, identified weaknesses in orchestration, retrieval, memory usage, and workflow structure, and then generated improved versions of the harness.
Instead of fine-tuning the model, it redesigned the environment around the model. In a sense, the agent became capable of improving the operating system it was running on.
Perhaps the most interesting finding wasn’t that performance improved. It was that optimized harnesses often transferred across different models. The reusable asset wasn’t necessarily the model. It was the architecture surrounding it.
That’s a profound shift in perspective. For years, we treated models as the primary source of value. These experiments suggest that structure may be just as important.
The New Bottleneck Isn’t Intelligence
One of the most surprising lessons emerging from this research is that more structure isn’t always better.
The natural instinct when building agents is to add.
More tools.
More verification layers.
More search loops.
More workflows.
More orchestration.
More control.
But some of the ablation studies revealed something counterintuitive. Certain components improved performance. Others had little impact. And some actually made results worse.
In other words, complexity isn’t automatically intelligence. A harness can become over-engineered just as easily as a product can become over-designed.
Which leads to an idea that keeps appearing across modern agent systems:
The subtraction principle.
Every component inside a harness exists because, at some point, the model couldn’t do something by itself.
But models evolve.
Capabilities improve.
What was once necessary may eventually become overhead.
The future of harness design may not be about continuously adding layers. It may be about knowing which layers can safely disappear.
What I’d Change If I Were Building Agents Today
The biggest takeaway from all of this isn’t technical. It’s strategic.
For the past few years, we’ve been conditioned to think that better outputs come from better models. So when an agent performs poorly, the instinctive reaction is predictable: try a different model, upgrade to the latest release, increase the reasoning budget, or expand the context window.
Sometimes that helps.
Often it doesn’t.
Because the real bottleneck isn’t intelligence.
It’s orchestration.
Before changing models, it’s worth looking at the harness itself. Is the context window carrying information it no longer needs? Are tools clear and reliable, or do they introduce friction at every step? Is memory helping agents stay grounded, or overwhelming them with stale information? Are verification steps genuinely helping, or simply creating more noise? Is the agent spending time managing complexity instead of solving the actual problem?
These aren’t the questions most builders started with a year ago. Yet they are quickly becoming the questions that matter most.
Because as models continue to improve, the difference between a good agent and a great one is increasingly determined not by the model inside, but by the system wrapped around it.
The Future Is Being Built Around the Model
We’ve spent years trying to build smarter brains. Larger models. Longer context windows. Better benchmarks. More reasoning.
And those advances have been remarkable.
But intelligence alone has never been enough. A brilliant mind still needs memory. It needs tools. It needs structure. It needs guardrails. It needs a way to turn thoughts into actions and actions into progress.
That’s the role a harness plays.
It’s the invisible layer that gives an agent continuity, context, and direction. The layer that decides what to remember, what to ignore, what tools to use, and how to move forward safely.
The next time you watch an agent navigate a repository, investigate a problem, recover from mistakes, and eventually arrive at a solution, remember that you’re not just watching a model work.
You’re watching an entire system think, act, and adapt together.
The brain was never the whole story.
And perhaps it never was.
Join Shweta on Peerlist!
Join amazing folks like Shweta and thousands of other builders on Peerlist.
0
1
0