Failure-First Thinking: What Live Data Systems Taught Me About Observability
How production failures reshaped the way I design backend systems
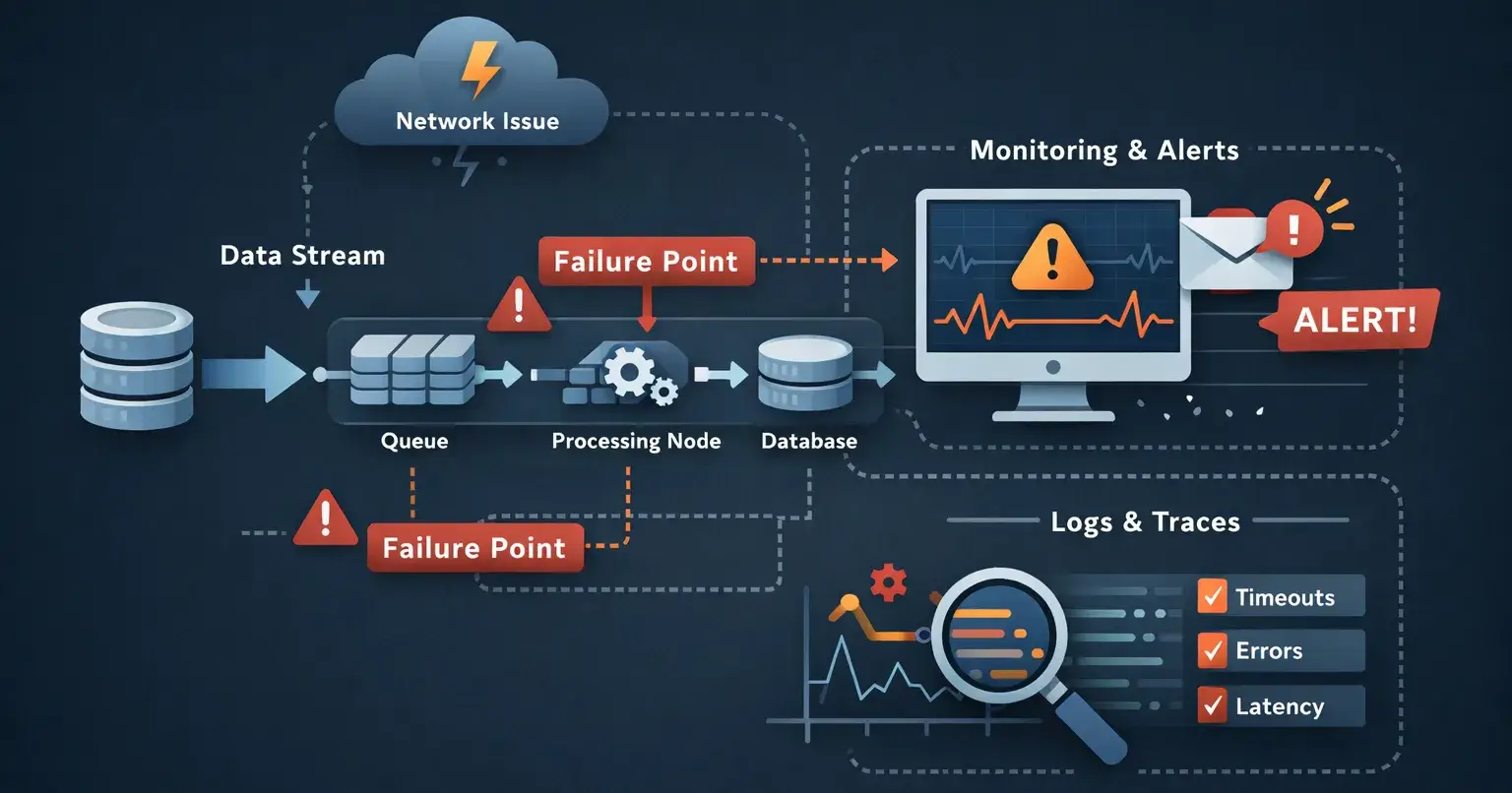
Working with live data streams changed how I think about backend systems.
Building features was rarely the hard part.
Understanding how those features fail was.
Early in my career, my approach was simple:
read the ticket, build what’s asked, move on.
If something broke, I’d fix it when it surfaced.
That approach works, until you start dealing with live systems.
The shift: from feature-first to failure-first thinking
At some point, I realized that most of my time wasn’t spent writing new logic.
It was spent debugging behavior under failure.
That’s when my questions started changing.
Instead of only asking “does this work?”, I now ask:
What happens when this flow fails?
Where can failures occur across the entire pipeline?
Are the risks network-related, latency spikes, timeouts, or race conditions?
How should the system behave when something goes wrong?
If it fails, will we have enough data to understand why it failed?
This shift happened gradually, but it changed how I approach backend development.
Failure points are everywhere (and usually invisible)
In live data systems, failures don’t announce themselves clearly.
They show up as:
delayed events
partial data
inconsistent states
silent retries
or systems that look “up” but behave incorrectly
Most of these issues aren’t caught during development.
They surface only under real traffic, real timing, and real dependencies.
That’s why optimistic assumptions don’t survive production for long.
Observability isn’t a tool - it’s a design decision
One of the biggest lessons for me was understanding that observability is not something you “add later”.
If logs, traces, and alerts aren’t designed intentionally:
debugging becomes guesswork
incidents take longer to resolve
stakeholders lack context when something breaks
Now, when I build a flow, I think about:
what information I’ll need when it fails
how quickly someone can understand the failure
whether the system fails loudly or silently
The goal isn’t to prevent every failure.
It’s to make failures understandable and actionable.
What changed in practice
Earlier, I mostly reacted to failures by rewriting parts of the system after incidents.
With experience, the approach flipped.
Now:
questions come before writing code
failure behavior is part of design discussions
observability is treated as a first-class concern
Live systems reward defensive thinking far more than optimistic feature development.
Closing thought
Handling live data streams taught me that stability doesn’t come from perfect code.
It comes from:
anticipating failure
designing for it
and making systems observable enough to reason about when things go wrong
Once you start thinking this way, backend development feels very different and production becomes a lot calmer.
Join Tahmeer on Peerlist!
Join amazing folks like Tahmeer and thousands of other builders on Peerlist.
0
2
0