What I Learned About the Hidden Cost of Database Indexes
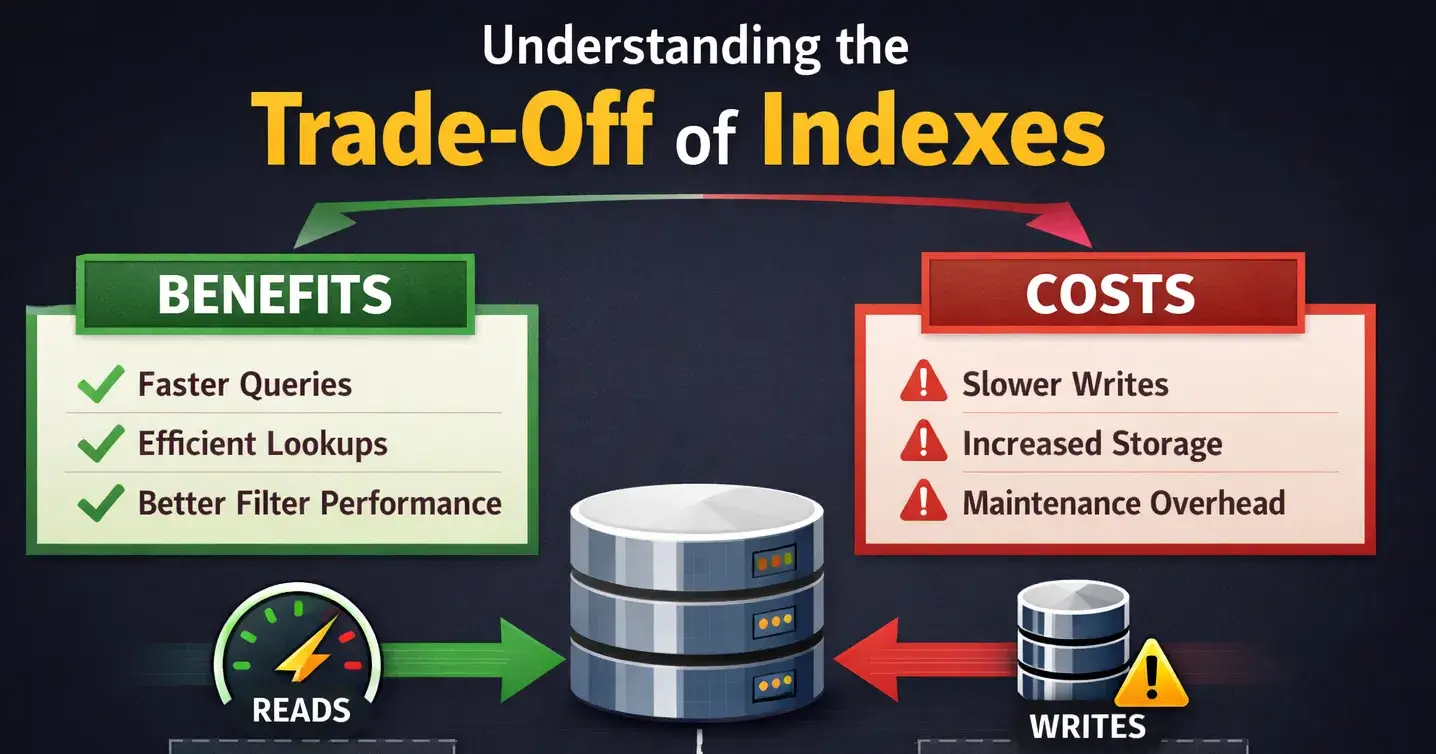
Understanding the trade offs of indexes
For a long time, my default reaction to a slow query was:
“Let’s add an index.”
And sometimes that works. Dramatically.
But while optimizing queries in PostgreSQL recently, I realized something important:
Indexes are not free.
They are trade-offs.
Here’s what I learned.
1. PostgreSQL Optimizes Cost - Not “Speed”
When we add an index, we expect the query to become faster.
But PostgreSQL doesn’t think in terms of “fast” or “slow.”
It estimates cost.
When you run:
EXPLAIN ANALYZE SELECT * FROM orders WHERE user_id = 101;
The planner compares:
Sequential scan cost
Index scan cost
Random vs sequential I/O
Estimated row count (cardinality)
CPU processing cost
If the index doesn’t reduce estimated cost enough, it won’t be used.
That was my first realization:
Adding an index doesn’t guarantee it will even be picked.
2. Cardinality Matters More Than I Thought
I used to think:
“If a column is in the WHERE clause, index it.”
But the real question is:
How selective is it?
Example:
SELECT * FROM users WHERE status = 'active';
If 90% of users are active:
The index still has to fetch almost the entire table.
A sequential scan may be cheaper.
High cardinality columns (like email or user_id) benefit more from indexing than low cardinality ones (like boolean flags).
3. Composite Indexes Changed My Understanding
I saw a case like this:
SELECT *
FROM orders
WHERE status = 'completed'
AND created_at >= NOW() - interval '7 days';
statushad only a few distinct values.But
created_atfiltered the dataset heavily.
Indexing status alone wouldn’t help much.
Instead, a composite index:
CREATE INDEX idx_orders_status_created_at
ON orders (status, created_at);
reduced execution time significantly.
The execution plan switched from a sequential scan to a Bitmap Index Scan, which batches page fetches to reduce random I/O.
That’s when I understood:
Index design is about aligning with real query patterns - not just adding single-column indexes everywhere.
4. Indexes Slow Down Writes
This part surprised me more than anything.
Every index is a separate B-Tree structure.
For every:
INSERT
UPDATE (on indexed column)
DELETE
PostgreSQL must also update every index.
If a table has 5 indexes, one insert becomes 6 write operations.
For write-heavy systems, this becomes a serious cost.
So now I ask:
Is the read improvement worth the write overhead?
5. Partial Indexes Are Underrated
Instead of indexing an entire column:
CREATE INDEX idx_users_status ON users(status);
You can sometimes do:
CREATE INDEX idx_active_users
ON users (id)
WHERE status = 'active';
Smaller index.
Higher selectivity.
Lower write cost.
This was something I hadn’t appreciated enough before.
6. Too Many Indexes Can Confuse the Planner
More indexes don’t always mean better performance.
If a table has multiple overlapping indexes, the planner must evaluate many possible plans.
With stale statistics, it can even choose the wrong one.
That’s when I understood:
Indexing is not “set and forget.”
It requires monitoring and periodic review.
7. When I Now Avoid Indexing
I now think twice before adding an index when:
The table is small
The column has very low selectivity
The table is heavily write-focused
The query runs rarely
The indexed column changes frequently
Instead of blindly adding indexes, I start with:
EXPLAIN ANALYZE
Measure first. Optimize second.
Final Thought
I used to see indexes as a quick performance fix.
Now I see them as a workload decision.
Each index:
Speeds up some reads
Slows down some writes
Consumes storage
Adds maintenance overhead
The goal isn’t to minimize indexes.
The goal is to have the right indexes for your workload.
Still learning. Still experimenting.
But this shift in thinking has changed how I approach database performance.
Join Tahmeer on Peerlist!
Join amazing folks like Tahmeer and thousands of other builders on Peerlist.
0
9
0