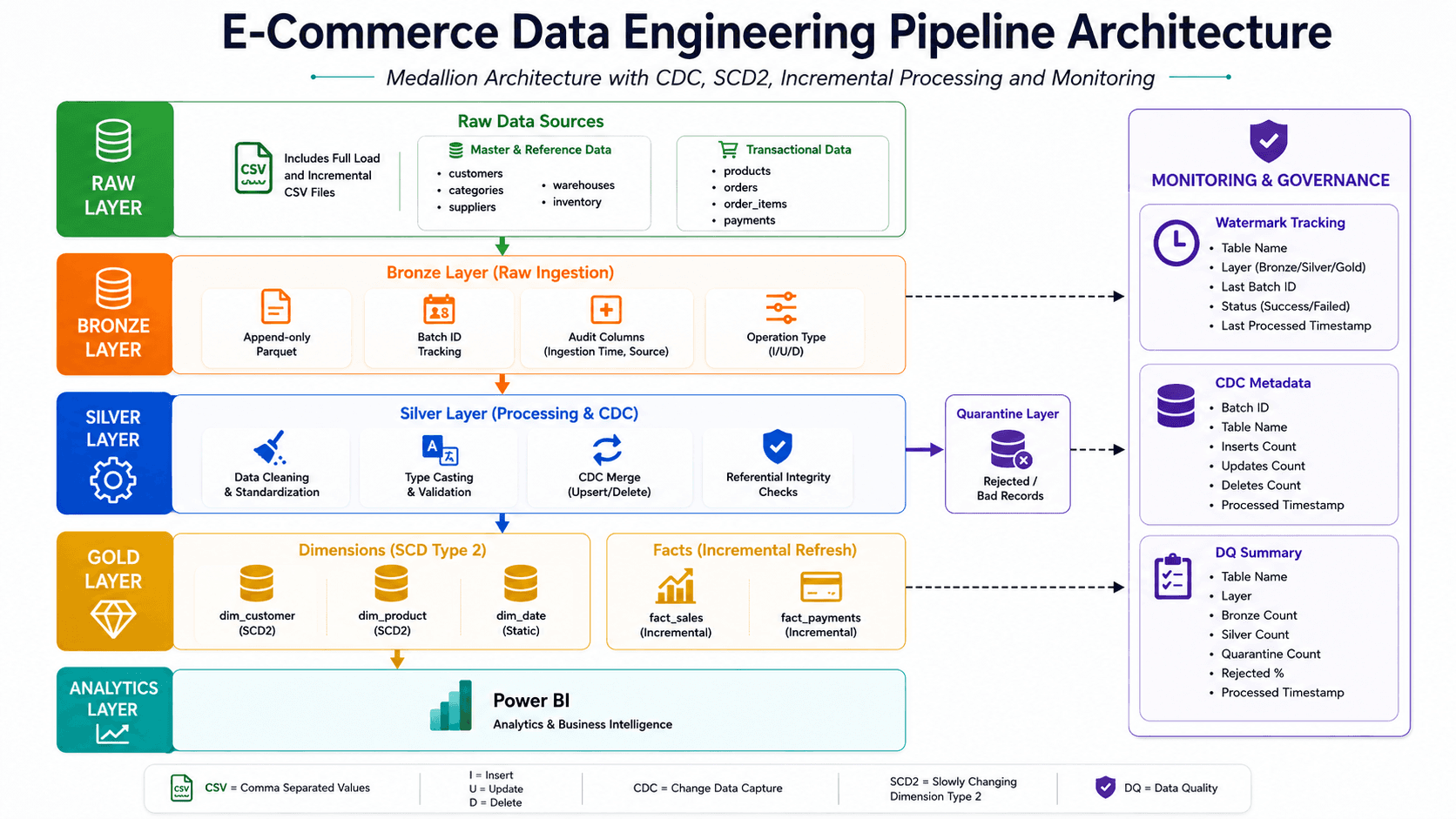
E-commerce ETL pipeline
3-tier Medallion ETL pipeline built with PySpark & Airflow.
- Engineered a scalable, 3-tier Medallion Architecture using PySpark and Apache Airflow, successfully automating the ingestion and transformation of 100K+ transactional records from raw state to production-ready analytical datasets.
- Designed an incremental Change Data Capture (CDC) engine to replace legacy full-table overwrites, dynamically processing, sorting, and merging source transactions (INSERT, UPDATE, and soft DELETE). - Optimized storage layer read performance by implementing Date Partitioning on Parquet files; successfully enabled downstream Partition Pruning, significantly cutting I/O latency for Power BI dashboard refreshes.
- Modelled the analytical Gold layer into an optimized Star Schema, decoupling transaction grains into highly structured fact tables and designing Slowly Changing Dimensions (SCD Type 2) to maintain strict historical data lineage.
- Established an audit-ready orchestration framework in Airflow utilizing high-watermark checkpoints and unique Batch_ID metadata tracking to guarantee pipeline idempotency and reliable failure recovery boundaries.
- Built an automated data validation and quarantine plane that routes corrupted or non-conforming records to an isolated directory while generating an operational Data Quality (DQ) summary table for immediate traceback and profiling.
Built with